Reminders about data-oriented design
I am from time to time "lost" in the data-oriented design practice having used to OOP for so long. This is a quick blog post that maybe helpful to someone out there.


I am from time to time "lost" in the data-oriented design practice having used to OOP for so long. By using data-oriented library, it is still possible that you are unknowingly doing OOP inside it.
Example problem : Massive Tic-Tac-Toe (MTTT)
Imagine you are building a tic-tac-toe (TTT) game, let's say not even a game. You are making a TTT library so whoever purchase this could make the most efficient TTT game possible. (Good enough frame rate, more resources for eye candies, more energy saved, slow down global warming, etc.)
TTT sounds simple and you may think you don't have to optimize it. But let's say we are going to install this TTT game on a very low end device that need the most enrygy saving as possible on Mars where it is hard to go replace the battery. Anyways, I will force you to optimize by making the problem more tangible, more massive.
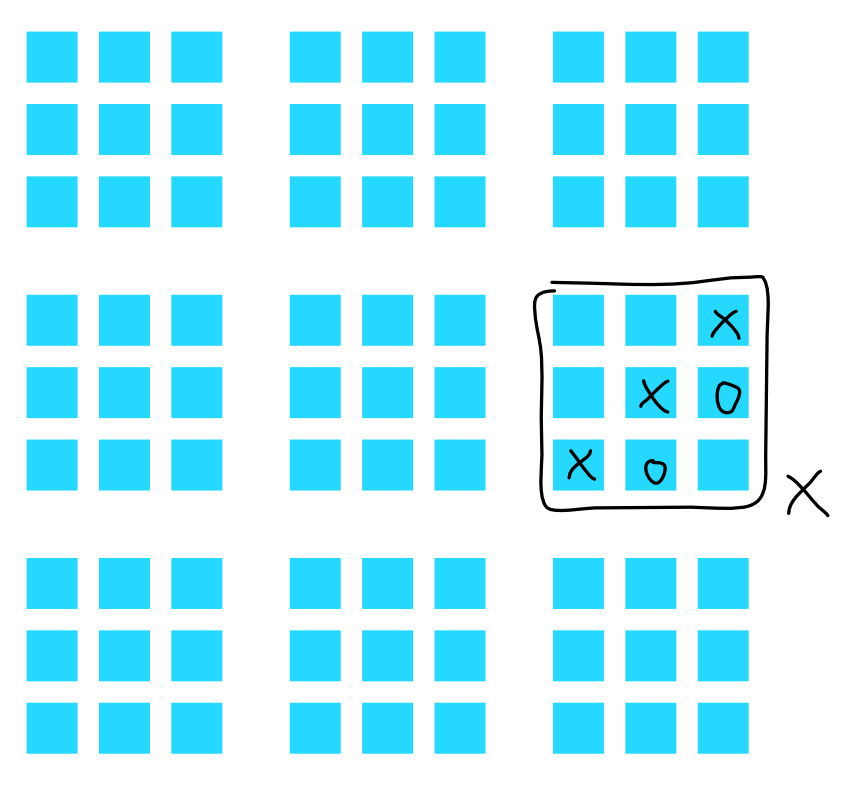
I am going to define "Massive Tic-Tac-Toe" (MTTT). Regular TTT game is a 3x3 grid. Now we can lay down that 3x3 grid to form a bigger 9x9 grid like sudoku.

Extra rules that you are required to code for this library :
- Each 3x3 grid can has a winner "3x3 win", according to normal TTT rules. A player nets moderate amount of points by having this state on the board.
- As you may have guessed, if you can cause a win on 3x3 smaller grid, it can become a "bigger win" when it lines up in 3, in the bigger 9x9 grid. You get huge amount of points by having this state on the board.
- To spice things up, the bigger 9x9 grid has a special rule. If you have 2 3x3 wins, but interrupted by the other player's 3x3 win on the center, you still get a "bigger win" anyways because you "pinched" it. This may allow unexpected comeback, I don't know.
- The game is played not by taking turns. Each player has 5 seconds cooldown after placing each symbol. You can place on any cell on 9x9 grid that is not yet a 3x3 win. This is just to make the problem sounds like the library must be able to produce the current score no matter when the symbols are added to the board. (Maybe you add some skills that can destroy the opponent's symbol, and the library should still calculate the resulting state out automatically.)
I don't know if this will be balanced or even fun, but let's think about how to code DoD to accommodate this requirement. This is what your library user wants :
- Able to draw the board efficiently at all times, given any current state of symbols on the board.
- Able to draw a visualization of which area on the board has been "scored", given any current state of symbols on the board. So you know when to play effects when it scored.
- Has a total score of both players calculated at all times, given any current state of symbols on the board.
Seems like data-oriented design, but turns out OOP
From tools given by Unity's Entities library, the past me would begin to reason like this :
- An
Entityrepresents each symbol on the board. (A dangerous thinking, as we will recap in the final section.) - A component
X : IComponentDataandO : IComponentDatatag component (no data), represent what kind of symbol that is, attached to the entity. - A component
BoardPosition : IComponentDatacontainingpublic int2 position;to say where it is on the board. - A plethora of systems that worked out the solution based on just these
XOandBoardPositionon entities. Mutate them, filter them, emit newScoreentities, and so on.
Sounds great, except that I thought that out for no reason. Actually the reason was kind of OOP, I automatically try to abstract the problem as objects for no benefit other than my understanding.
I thought I was ready but I was still half-OOP. I didn't think about what the data would look like as the result of attaching O or X, just because I want it to be called more tangibly O and X. I wasn't solving the problem by data at all.
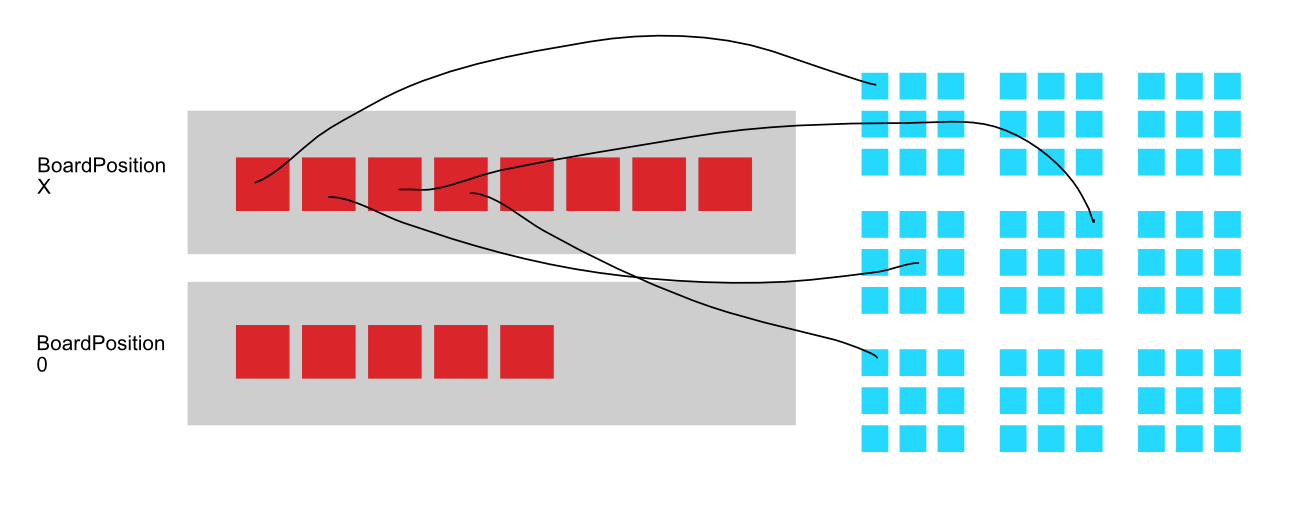
What if I told you that design results in this 2 chunks layout in memory :
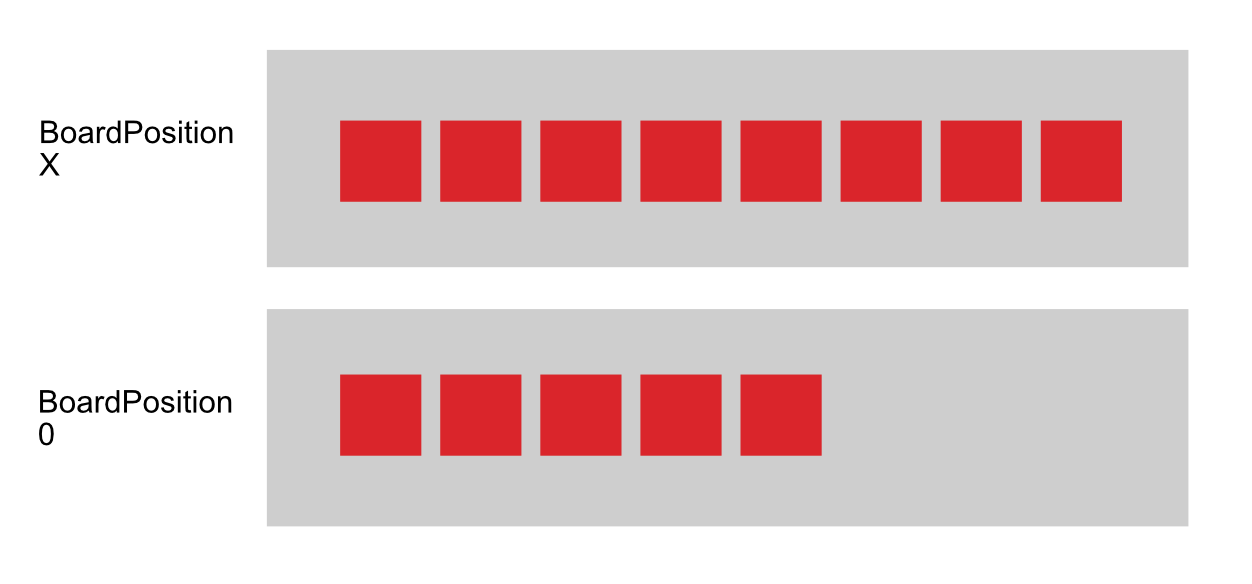
Where each grey rectangle is a chunk, thus guaranteed contiguous memory and fast iteration. Unity chunked our entities based on archetypes. In this case we have 2 possible archetypes.
Taking the word "data-oriented" more seriously
Here's the reason you want to keep in mind to make it a proper data-oriented design : make the most statistically common path the fastest. And what is the fastest way of doing things? Having them lined up in memory and iterate linearly though them, do the same thing to all of them, without caring about order because they are independent. Therefore you must think of data instead of abstraction to achieve this goal. (Also multithreading, and fewest cycles of assembly opcodes.)
In the prior result, ask your self "do you ever wanted to linearly iterate just X and just O linearly the fastest?". If no, then this design is a failure no matter how tangible it is in OOP-thinking. It's bad enough that it is an uncommon case, but the worst is "not ever going to".
If TTT is simply a game of "whoever place the most symbols on the board wins", then I think this solution is one of the best. Since to count score for each side we can blazingly iterate fast. One time thorough all X, then one more through O.
But our rules needs :
- Iteration/checks in each 3x3 grid.
- Iteration/checks through larger 9x9 grid with some exotic rules.
And this data structure didn't benefit either case that should be the priority. That linear memory earlier maybe representing these far away symbols. Being able to linearly iterate thorough these the fastest, is not useful as no scoring rules are covering them.
It maybe great for drawing code if drawing just X then just O (batching) results in a better performance. That is the case that you have predicted the most statistically common code path is going to be an iteration for drawing. For this article's purpose we assume that the correct answer is to optimize for rule checks. (In real case you need to profile, roughly predict.)
It is useless to abstract the problem for no reason / for OOP reason. Don't be shy to design and talk directly with words like "data", "cache line", "these things are linearly stored", etc. Because this is literally "data-oriented design". You orient your design on data, it is not just that you use Unity's Entities methods to create the game then you have designed in a data-oriented way.
Therefore let's think more data-oriented. "Because I think the code is the most active in always checking each 3x3 grid, I want each 3x3 grid data to be more linearly arranged." Now that's more reasonable thinking in data-oriented, but still maybe right or wrong, you need to profile.
To chunk them out, instead of tagging BigGrid11 : IComponentData BigGrid12 : IComponentData and so on, Unity has ISharedComponentData which can chunk things out by unique value instead of by component type. Let's say BigGridPosition : ISharedComponentData { int2 position; } where each position could be (0,0) to (2,2) to define which group of smaller 3x3 each symbol is on. There are 9 possible positions in this shared component.
We are now talking data. All the things are not an organizational tools like OOP anymore, everything are for the purpose of changing data location and we must talk about that directly. BigGridPosition sounds mildly organizational, though our real purpose must be in the head : "I want to chunk the data according to this." It's not you-know-who, you can say you do this to make the data looks like this. (Which may sounds stupid in OOP, if you say this class is there to change the data layout. In OOP the class group things to one unit that could performs work on its own.)
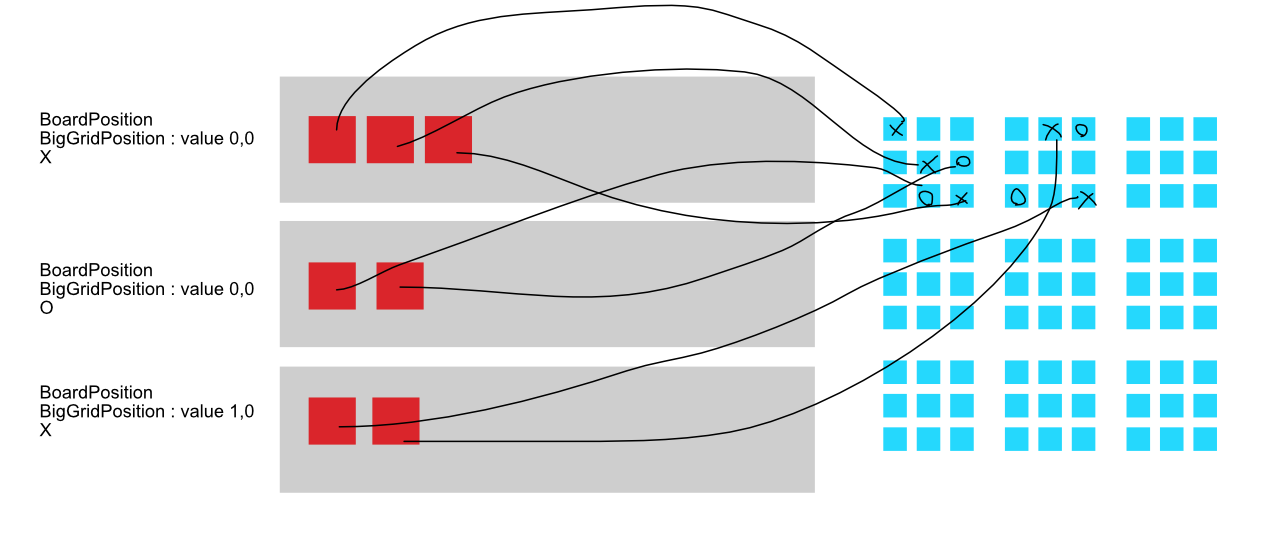
By using ISharedComponentData we notice that related entities are now more in the same chunk. There is one thing not ideal, you notice in the top left 3x3 grid there is a battle going on and you would like to constantly check when it is going to be a score, but you are always require to iterate across 2 chunks because O and X component separate them away to a different chunk. It's time to ask whether this is a good design or not :
- It maybe possible for a game of TTT to determine 3x3 winner by iterating just one chunk of either
OorX, if you found that it is winning there is no use to check for the other symbol type. By this reasoning, the current 2 chunks ofXandOseparately is already good. - In the future you want to implement more rules inside each 3x3 grid where it is required to check for both kind of symbols. For example you can do a "pinch" in this smaller 3x3 grid. In this case merging chunk sounds like a better idea.
- You think your cache line is not big enough to hold 9 consecutive symbol data, so you think merging chunk for
OandXis a bad idea. (given that common cache line size is 64 bytes, it is unlikely) - The symbol placement code may benefit from having a chunk of mixed
OandXtogether, it is not just for this scoring code. - If you assume common cache sizes is 64 bytes, it may seems like even a chunk separation that sounds wasteful, is able to benefit anyways because each component in the chunk is way larger than a cache line.
- To think more : (you should for the sake of practicing DOD even if you choose to not care in the end), in merged chunks the most demanding case is a lined up 9
int2of positions you are going to iterate through (without worry about symbol type, maybe just to draw them not to judge) each one 8 bytes, so 9 of them total to 72 bytes. It is a bit more than 64 bytes, so in this case 2 cache lines read for 64 bytes machine if you merged chunks. If you didn't then it is 2 cache lines read always even if you have 1 X and 1 O each in 3x3 grid. In the worst case that O played 8 times and X played 1 time in this 3x3 grid, O player will fully fill one cache line of 8*8 = 64 and you spend one more for X on the other chunk.
But this case is not the most common code path statistically at all, it is very likely that players will try to fight in the same 3x3 cell resulting in half-half of O and X. And when we mention 9 fully filled O and X in the merged case producing a bit over 64 bytes resulting in 2 cache lines, that is not common either because there is a rule in place that you cannot continue playing on the same 3x3 grid if a winner has already been determined. Also when both players see that the only outcome is a tie, they may not continue playing on that 3x3 grid even if more moves are possible. I then predict that there will be about 6 symbols per 3x3 grid on average.
Therefore finally! 6 symbols producing almost always under 64 bytes if players are not that stupid and place a non-winning position for the sake of filling the cells, and overall results in 1 cache line. 1 vs 2 seems small, but this maybe 2x speedup if this is all you do every frame. Remember that later memory level is exponentially slower, RAM is very slow compared to L1 cache, so cache missing is actually costing more than that. End of overthinking, but I think it is healthy if we are doing data-oriented and not OOP.
Think if your O and X are there for no reason / OOP reason or not. It depends, but now I assume we decided to merge chunks and therefore remove O and X component no matter what how wrong that feels. There are 2 approaches to remove O and X with different result on data :
- Keep the
BoardPositionbut make a newSymbolType : IComponentDatawith a singleenumsaying what it is. By doing this, inside one chunk you get a linearly lined upBoardPositionthen linearly lined upSymbolType. This is good when you have an algorithm that wants to run through and just check for symbol type. - Changing
BoardPositiontoSymbolData : IComponentDatawhich contains both position where in 9x9 grid and additionally what symbolenum SymbolTypeit is as a field instead. By doing this, you get a linearly lined upSymbolData, which contains the position and symbol type. So in the end it is an alternating position and type. This is good if you always need both at the same time and give convenience in creating query.
Both are valid approaches and merge chunks the same, after you decided on which (the image depicts SymbolData approach), now the chunks looks like :
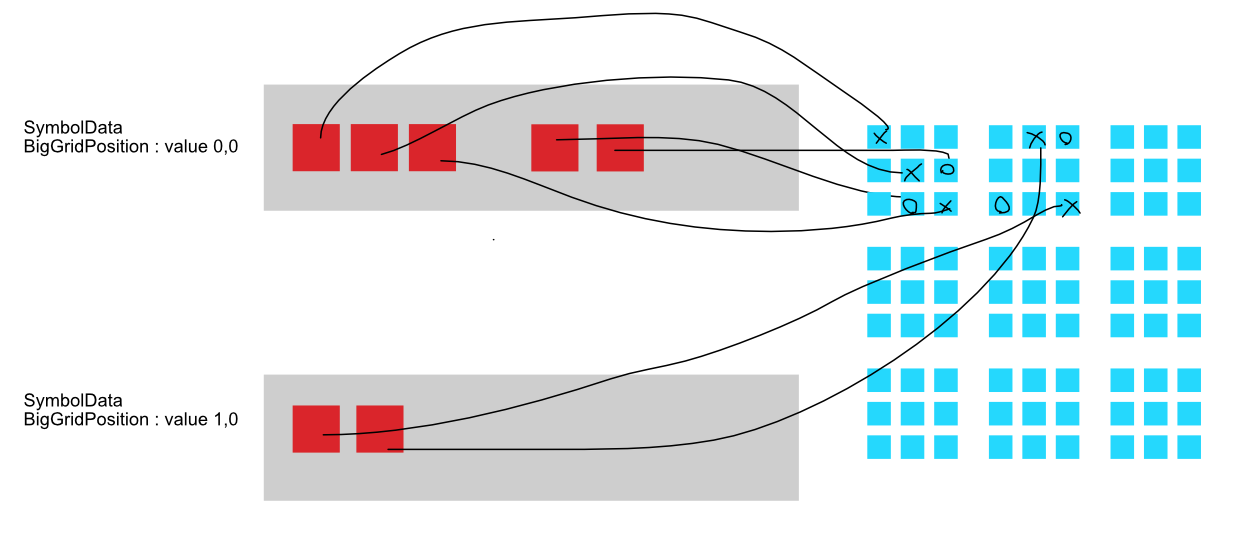
Previously it was :
Now this library ensure each 3x3 grid can be checked for valid pattern faster since the cache line will have more chance to contain everything in each 3x3 cell.
And you have to know too that each of these grey rectangle is a fixed 16kb size of space in the case of Unity Entities library so to go from the end of one to another that's quite far away that there is no hope of cache line connecting, or maybe any other rules in other libraries, I don't know maybe Unreal has one that let you line up memory in the future. But the point of data-oriented is that you are always aware of data.
These memory details of when will which line up with which and when it skips a long distance is not intimidating at all, because data is now the first-class problem you have to work with! Actually you should be glad that you can exactly picture how your data ended up like without any debugging tools, unlike when you were using new in OOP. This is how you more literally working "data-oriented". Shift your focus away from "objects". It is not just you design in "object" and that somehow turns into data-oriented. (Though, Unity's Game Object Conversion Workflow allows that to an extent. Game Objects are human concept.)
However not the same could be said about our extra rule that scores in a bigger cell. If I introduce an another rule that this column or row move scores million points, then the old design requires iteration across at least 3 chunks or at most 9 chunks of possibly non-contiguous memory. Also think if this case is a rare or common case, is it worth optimizing for this case? If you can begin thinking like this, I think it is closer to data-oriented now. You worry about data more than abstraction.

If you chunk the data so they are linearly in column, maybe row checks are now slower. Maybe 3x3 checks are now slower. How to fix all that maybe, you can duplicate data acorss multiple kind of chunks but each duplication is optimized for each kind of checks. But duplication adds up to difficulty of maintenance. Data-oriented approach gives you this performance vs. code choice. OOP give you no choice before.
Stoyan made an optimization for web games animation with data-oriented design with good results and there are multiple of the same data down the data transformation pipeline. That's completely fine, we are finally freed from object-oriented programming. There is no need to find a reason what to call the duplicated data anymore (what is it in terms of object?), we have duplicated data for reasons. It's in the design.
All these reasons sounded wrong in OOP. No matter what the problem you have you still keep your things as O and X. Data duplication sounds like a word from hell. In OOP you keep data in a place "somewhere" you don't even care, and distribute references to other objects.
But now they are all good. We are solving the actual problem here (the best library in the world to make an efficient MTTT game), not the best looking code or the most closest to real world code. You as a programmer see in the code that this thing is X symbol and this thing is O symbol, is not the real problem. Your user will appreciate the performance, not the code.
Then we have more to think also. Maybe you are too focused on the cache line but not the cache size. Even though the chunks are spreaded out, cache eviction will not happen yet if you come back to visit old data not too long after. The cache line thing helps give you a boost in the sense that you get free stuff on one load that could have been a junk, but even without that, you can value simpler code more but still not neglecting the overall shape of data and what is the current state of the cache in your head. The same reason if chaining adds complexity and is the root of bugs because you thought it should be going that way but it wasn't causing behaviour bug, a misunderstanding in state of cache leads to performance bug. Data-oriented design allows you to understand the state of cache better at the same time potentially elimitating if, reducing both kind of bugs.
Talking about "easy to reason" code : it doesn't mean data-oriented is now a mess of cryptic code. It should be (instead) easy to reason about performance. A shift in paradigm from OOP where we made it easy to reason about how things interact with each other. If we look at one glob and have no idea is that expensive or not then it is probably a code smell in data-oriented.
It still give you maintainability, but maybe a different perspective of it. In OOP, you want to add a bool to add function A, you know it is going to be appropriate on this object A and it is not going to break anything else thanks to your superior object oriented design, plus related objects get inheritance. In data-oriented, you know that adding a bool at the end of this stuct is not going to break a cache line and still allows vectorization. Data-oriented extensibility is there too, adding functionality maybe just a matter of adding a new linear array somewhere.
I will show how to overthink one more time. Which could results in an optimization. This is assuming we took the approach that has 2 components of BoardPosition and SymbolType separately, so requesting an iteration on just BoardPosition could go ahead without SymbolType in-between.
- The position doesn't need to be
int2, it can even be a number from 0~8 signifying each cell in 3x3 grid. You can use abyteto get more room for other things or use bit operation to get it even smaller since you need just 4 bits to store 9 different numbers. What was sounding like the root of all evil feels like a "legal" thing to do now that data-oriented goal is to design data. One cache line that represents the whole 9x9 grid maybe possible now, it may greatly boost drawing speed where you must read the entire board regardless of rules. - If you somehow got more things like what timestamp the player place each symbol, what race and elemental attribute (lol) each symbol is, or an IP address of the player if this game is open to the public on the net for anyone to place symbols. It may make sense to group these additional data to
SymbolMetadataas you feel like it is a hassle to make a new component for each (a pain to create a query in Unity DOTS, etc.), but still separate theBoardPositionout as a special case for the sake of linear data layout for all positions. The data-oriented reasoning is drawing the board is the most important and you still want these positions lined up in the chunk without anything else in between. You have balanced your design by properly reasoning the data.
"What is my Entity"?
To end this article, I observed that this is the root of misunderstanding about data-oriented design when I was starting out. Immediately after learning enough and I went start creating, I was finding what would be called an Entity in every situation so I can finally code.
That "what" is already a synonym of an object in my head but I wasn't aware. And this thinking is dangerous that you may ended up with OOP-in-DOD.
For example in this TTT situation, the thinking that each symbol on the board is an Entity kind of work out, but it prevents some other data-oriented designs such as "TTT symbols but aligned linearly in 9x9 grid instead of 3x3" because you think " Entity is already representing TTT symbols, why do we have that again?".
This thinking also usually leads to something like bool in a component because you think it is "appropriate" (in human, worldly thinking) if that object should have that state attached, an awfully OOP concept in disguise of data-oriented, which leads to if checks, that could be prevented by instead having 2 chunks of one that is "yes" and one that is "no" so you don't have to if and just iterate on the one that matters.
It was repeatedly reminded by Unity that "Entity is just an ID and has no data or behaviour." But the loophole is that because it is "just" an ID, we could anyways associate each ID with an object, because ID could be anything, including an identification of an "object". I think that definition was not enough to keep me not strayed back into OOP sometimes.
I find it more helping to think that Entity is strictly a label of a slice of data. That should always be your "what". Not representing any human world concept. (Though sometimes it accidentally represents an object and is performant at the same time, in that case, great.)
External resources
Feeling pumped to design data and out of object-oriented cage? Read this book : http://www.dataorienteddesign.com/dodbook. All of it is a revelation. I have no idea we could take an innards of an object out like a serial killer and line them up with Relational Database techniques. I have not look at each if that there is a way to naturally remove them before just by not doing OOP.
If you got about 2 hours you maybe interested in this talk :
Do watch the Q&A section and think for yourself about this performance-constrained or engineer-constrained thing. Roughly, if data-oriented make it less productive to actually ship the software will it worth the performance? OOP is designed for that strength and does not need to "die". OOP is natural to reason and code, may leads to a test of one object that could be reused and ensure it still works, just that any concerns about machine ("the platform") is not in the design. It's about you the programmer. Unity is trying to make data-oriented both performant and reasonably flexible for future change and easy to code (e.g. the fool-proof C# Jobs System), though it is unproven. DOTS is not even done right now. Who knows what will happen.