Analyzing Burst generated assemblies
In this article, I will challenge Unity's Burst compiler with various job code, and we will along the way learn about what's performant for the game. Get ready for the great assembly adventure, Unity had never been so hardcore about stuff this low level!


In this article, I will challenge Unity's Burst compiler with various job code, and we will along the way learn about what's performant for the game.
Get ready for the great assembly adventure, Unity had never been so hardcore about stuff this low level!
*Everything here is compiled with Burst 1.0.0 preview 8, by the time you are reading this it could be much more intelligent.
Preface : Where is the performance?
In Unity DOTS, they promised performance from several sources.
- Keep the worker thread busy working while not driving you crazy while programming it, achieved with C# Jobs and further streamlined with
JobComponentSystemwhere it connects to the ECS database directly. I am so glad we don't have to do mutex stuff in the game at all yet all the reads and writes are already avoiding/waiting each other beautifully! - Exploit spatial and temporal locality of reference. When CPU have to get something from RAM to the cache, it should dragged in as much related stuff as possible, and not have to get them again as long as possible. Ensured with custom made tight ECS database. The C#'s default
newon theclasswill destroy this at almost every.you use. - The generated assembly is smart, use only the good stuff. Ensured with Burst + HPC# coding restriction that eliminates the case that could not be optimized. After that, we optimize what could be optimized. <- This article's concern. What are those?
Programming games in traditional OOP destroys everything mentioned thanks to the evil reference type. That's why Unity is building a new foundation from the ground up that makes working with struct type bearable, automatic optimization possible, (and fun).
Preface : In the end we all become one with the assembly
Did you have elitist programmers in your social network? They started programming in high school and now keep saying C++ is the best and today's programmers "have it easy" with C#, JS, etc. ? Kids nowadays have no knowledge of basics and goes straight to popular libraries / NPM ? These kind of guys sometimes are just not pleased that others don't have to go through SIGSEGV as they did.
(I once met this kind of programmer at a job interview. Got tasked to do bubble sort by hand on the whiteboard, forgot the concept and doesn't allowed to use Google so I failed the interview lol)
Turns out all that matters is the generated assembly instructions. With Burst we are trying to make the best assembly from C# while saving you from SIGSEGV. The generated code is like you are using pointer arithmetic, without actually using them. Before that, some terms.
Terminology
Word size depends on architecture (32/64), but for some reason when you see "word" in assembly language that means 16 bits. So for some example :
- Byte integer =
byte(8) - Word integer =
short(16) - Double word integer =
int(32) - Quad word integer =
long(64)
For example the register xmm is of size 128 bit. You could say one xmm is able to hold 2 quad words, or 4 double words, or 4 int.
Instruction set architecture, is.. assembly is not actually a language but a category for all of that kind of languages "for CPU". Those language basically just load, calculate, and store stuff. But we have been making wonderful creations from just that.
Everything in this article is based on Unity's "auto" settings. This settings seems to select the most cutting edge of x86-based instruction developed by Intel.
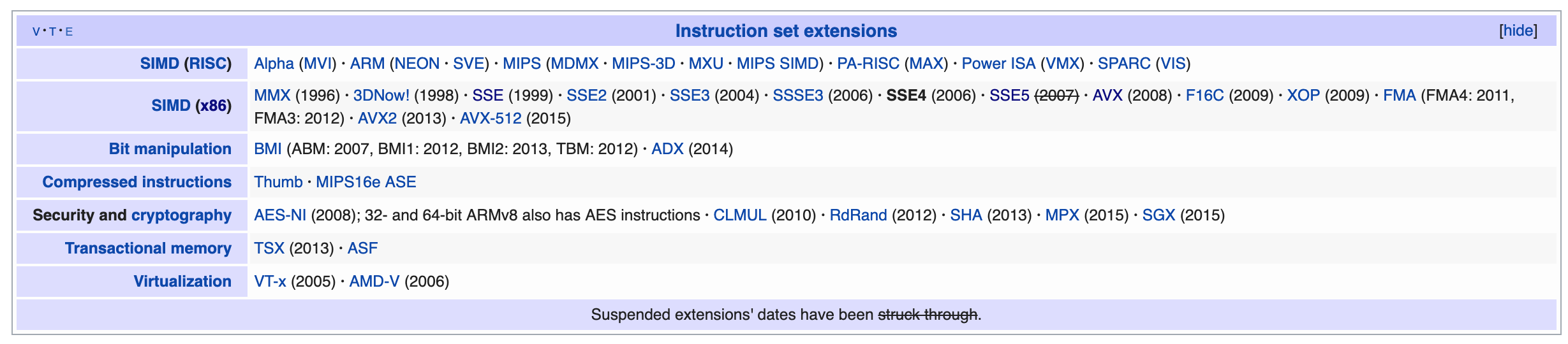
x86-style instruction do receive upgrades and new instructions to play with over time. For the evolution timeline, I will just borrow Wikipedia's bottom section here.
And so with "auto" I think Unity is choosing AVX512. For example it comes with some great commands like "fused multiply and addition" at the same time. (Seen as vfmadd231ss in the image, which fmadd stands for that) If you select a lower patch in the drop down, you will see the debugger adjust accordingly with alternatives.
With that out of the way, the source of all performance is choosing the good stuff. You can tell what is a good stuff by...
Command that do work on a big register
When you see a register like xmm or ymm being used, you could guess it is doing a good chunk of work since the size of that register is 128 and 256 bit respectively. Many commands accept this big register. You could just search in Burst debugger and see if there are any xmm or ymm instead of knowing which command supports big register.
However sometimes it do use xmm for a single value operation! So it is not 100% that it is doing a tons of work.
Command's option
For example, this command is a good one.
vmovapsmov is just moving data from one register to an another. But look at the options!
v= vector extension, specifying that it supports the VEX extension standard. (https://en.wikipedia.org/wiki/VEX_prefix) There is also an upgraded version called EVEX prefix and they also usevprefixed opcode.a= aligned : Usable when the data aligned with "word size" of the machine. (Ifu= unaligned) I guess when this is present it means the command is more efficient?p= packed : It uses packed arithmetic. I don't know about it much but it is something that could compute floating points in integers, increasing speed. (You could read more here) Sometimes when it is not packed you seesfor scalar instead. In some place on the net I read, packed is called vector.s= single-precision : When you do something tofloatit is bound to be faster thandoubleat assembly level. If you seesssomewhere it probably stands for scalar + single-precision.
From these you could understand what is vadd and subps for example. If you are too lazy to remember, just look for the a or p because that's usually a good variant. (More examples)
But imagine if you are roleplaying as a compiler that tries to compile C++ to assembly. You would have a very hard time finding place to use the p or a variant! Or thinking should we do it little by little or could we use ymm? Or the half sized xmm?
Luckily we got High Performance C# subset and the no-mercy Unity code analyzer. It became easy for Burst to just add the good stuff everywhere without worry. (Worry = aliasing problem, reference fields, ...)
For assembly reference you may have this handy while debugging your bursted code. Just make sure you are using "auto" or x86 based instructions.
LLVM
This is an excellent talk from Unite LA 2018 explaining why are we standing on top of existing LLVM :
Before we witness the optimization it is helpful to know that Burst is using low level pieces from LLVM. And there are many optimizations available in there : https://llvm.org/docs/Vectorizers.html.
However we have to still credit Burst and DOTS design that enables optimized use of LLVM in the first place, all in a nice C# environment.
The big registers : xmm ymm optimization
From the official Burst documention
https://docs.unity3d.com/Packages/com.unity.burst@0.2/manual/index.html#supported-net-types
Note that for performance reasons, the 4 wide types (float4,int4...) should be preferred
We will see the assembly why that is the case. If you read the preface, could you guess what would make a difference in the final product?
These 2 jobs just copy data. But one struct is float3 and one another is float4. Did your intuition say that more data must cost more performance?
public struct S1 : IComponentData
{
public float3 xyz;
}
public struct S2 : IComponentData
{
public float4 xyzw;
}
[BurstCompile]
public struct J1 : IJob
{
public NativeArray<S1> s1a;
public NativeArray<S1> s1a2;
public void Execute()
{
for(int i = 0; i < s1a.Length; i++)
{
s1a2[i] = s1a[i];
}
}
}
[BurstCompile]
public struct J2 : IJob
{
public NativeArray<S2> s2a;
public NativeArray<S2> s2a2;
public void Execute()
{
for (int i = 0; i < s2a.Length; i++)
{
s2a2[i] = s2a[i];
}
}
}
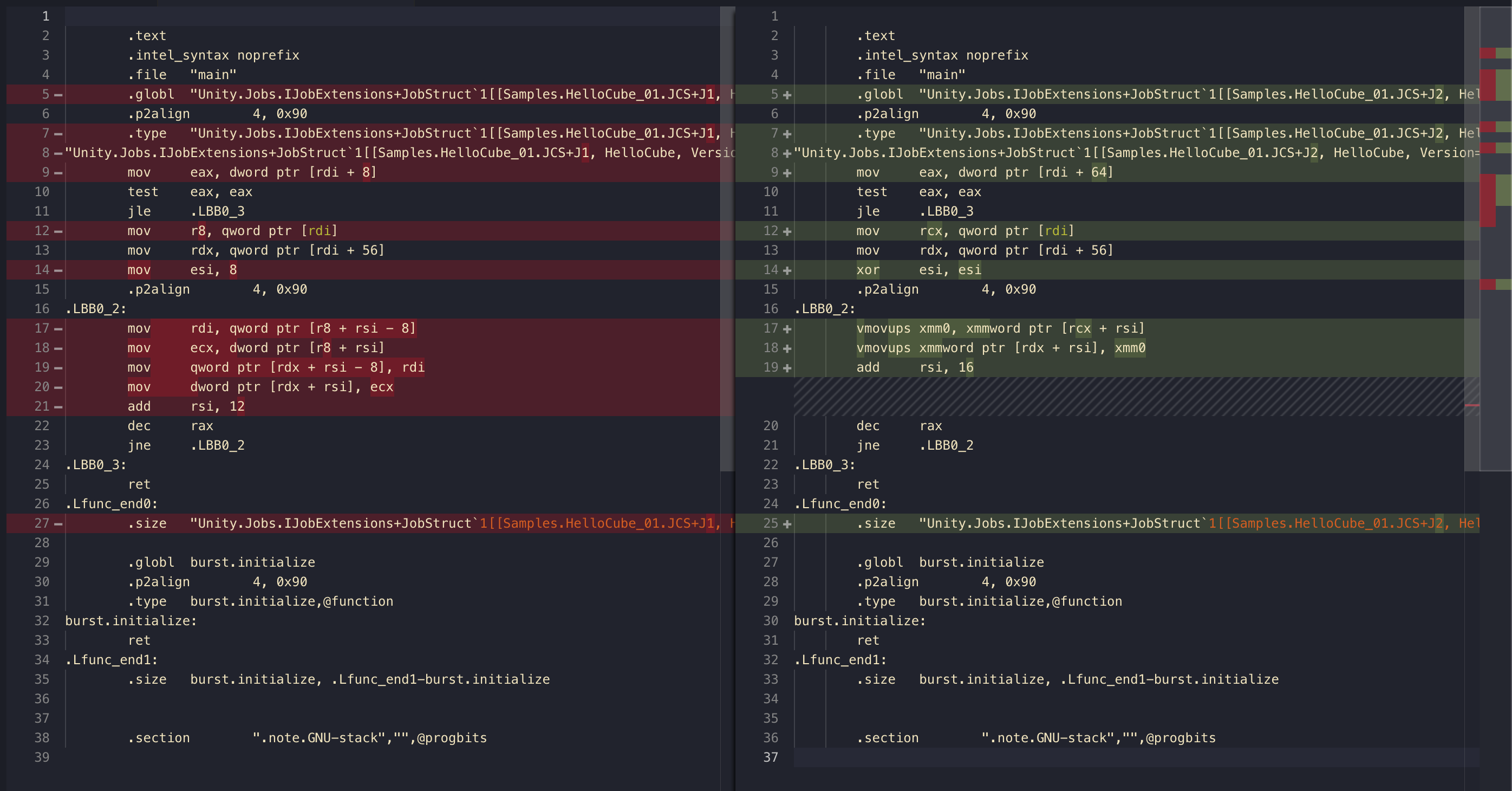
Left is J1, right is J2. The mov, jle , and then later add is obviously the for loop's condition. In between must be what we are looking for.
Left side, Intel's terminology says word is 16 bits regardless of architecture. So what it is doing is move quad word qword and double word dword to store in temp register rdi and ecx then move from that to the destination location. Quad and double happen to sums up to (16 * 4) + (16 * 2) = 32 + 32 + 32 and that's 3 float. You see Burst is trying to be smart about the first 2 float too.
But the right side is vastly more efficient. You see vmovups and you recognize the xmm. That must be a good stuff. I don't know how to write a code so that it turns u (unaligned) into a (aligned), but maybe it is impossible to determine here if our NativeArray is aligned or not, so we get u.
xmm is 128-bit register! (Maybe unavailable in some machine, but we should assumpe it is available) We could store a whopping 32 + 32 + 32 + 32 bits here and this is exactly what we are doing. Use xmm0 as a temporary storage for a bit, then copy in packed mode to the destination thanks to the packed command p.
Though, on both side you may wonder why it copy to a temporary register before meticulously pouring that into the destination. Why not just do a direct memory copy? Actually assembly could not put memory operand on both sides. This packed copy is the fastest.
Also don't forget the [ReadOnly] on the NativeArray that is not the write target. It won't help generate any better assembly but will help Unity complete as less job dependencies as possible, making ECS less defensive (and go offensive).
Summary : Good assembly code used big registers for you, even though what you did in the code was far from it.
Deliberate padding
This time I use float3 on both, but one starts at offset 4! Pack on the StructLayout is not usable with Burst, we are making an empty hole manually instead with LayoutKind.Explicit.
public struct Unpadded : IComponentData
{
public float3 x;
}
[StructLayout(LayoutKind.Explicit)] // <------
public struct Padded : IComponentData
{
[FieldOffset(4)] // <------
public float3 x;
}
[BurstCompile]
public struct UnpaddedJob : IJob
{
[ReadOnly] public NativeArray<Unpadded> source;
public NativeArray<Unpadded> dest;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
dest[i] = source[i];
}
}
}
[BurstCompile]
public struct PaddedJob : IJob
{
[ReadOnly] public NativeArray<Padded> source;
public NativeArray<Padded> dest;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
dest[i] = source[i];
}
}
}
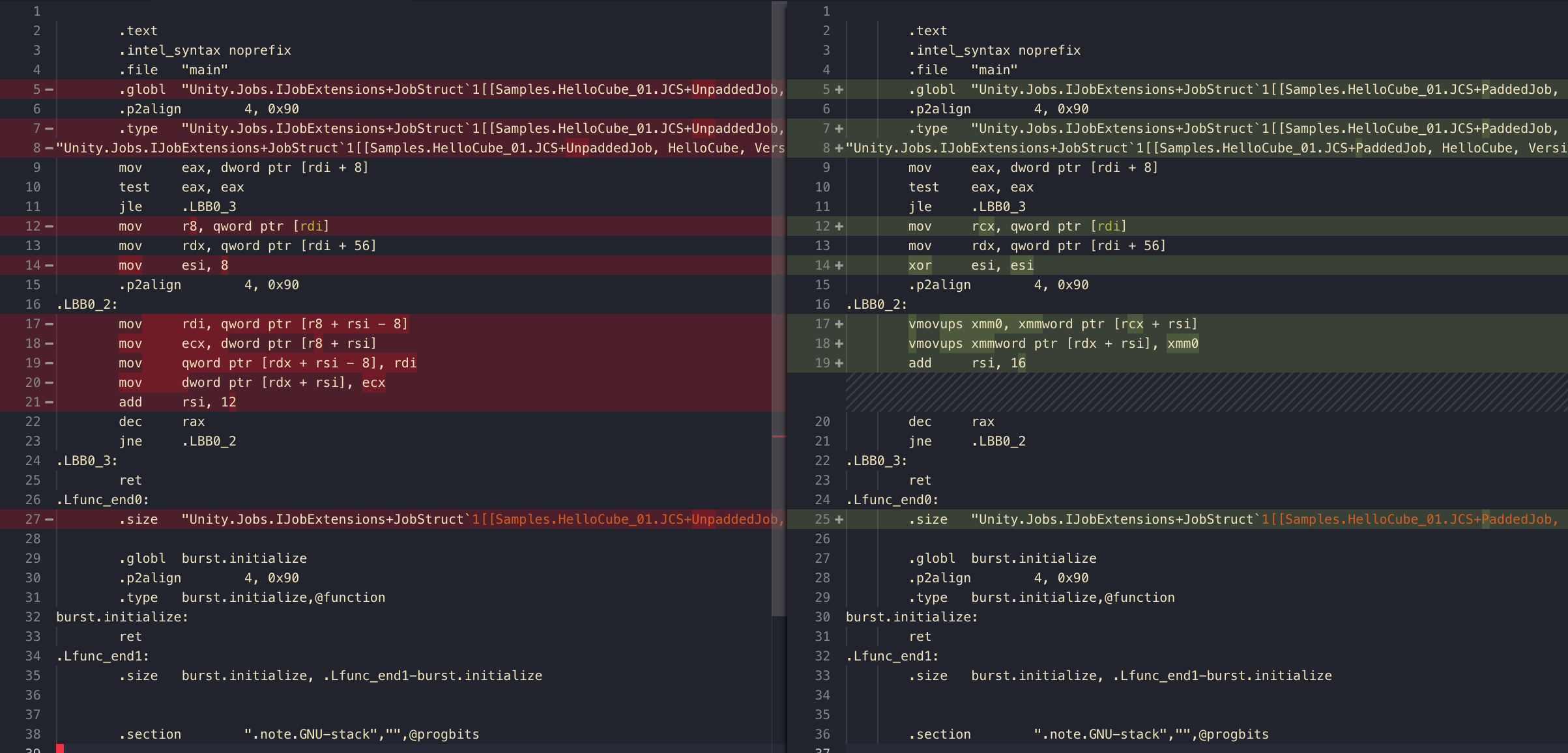
Turns out this time we could also get vmovups upgrade even with float3 type! Burst seems to know that the struct is of size 4 bytes and able to be in ymm nicely, no matter we intentionally make a hole or not. Note that this optimization is possible because it is a copy job where we don't need each individual value.
4x float vs float4
From the deliberate padding test you see Burst knows how to merge variables. In the prior case, it knows that " [empty] + float3 ... ok, let's just use xmm0 and copy the beginning space (whatever it is, an undefined memory?) altogether!"
We will challenge it with an another test.
public struct S1
{
public float x;
public float y;
public float z;
public float w;
}
public struct S2
{
public float4 xyzw;
}
[BurstCompile]
public struct MergeThis : IJob
{
public NativeArray<S1> source;
public NativeArray<S1> destination;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
destination[i] = source[i];
}
}
}
[BurstCompile]
public struct Normal : IJob
{
public NativeArray<S2> source;
public NativeArray<S2> destination;
public void Execute()
{
for(int i = 0 ; i < source.Length; i++)
{
destination[i] = source[i];
}
}
}
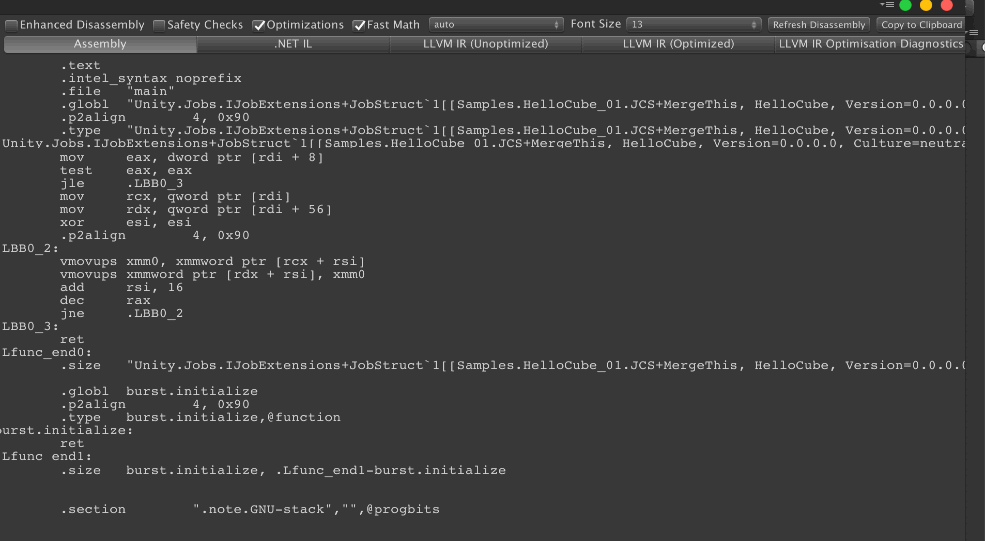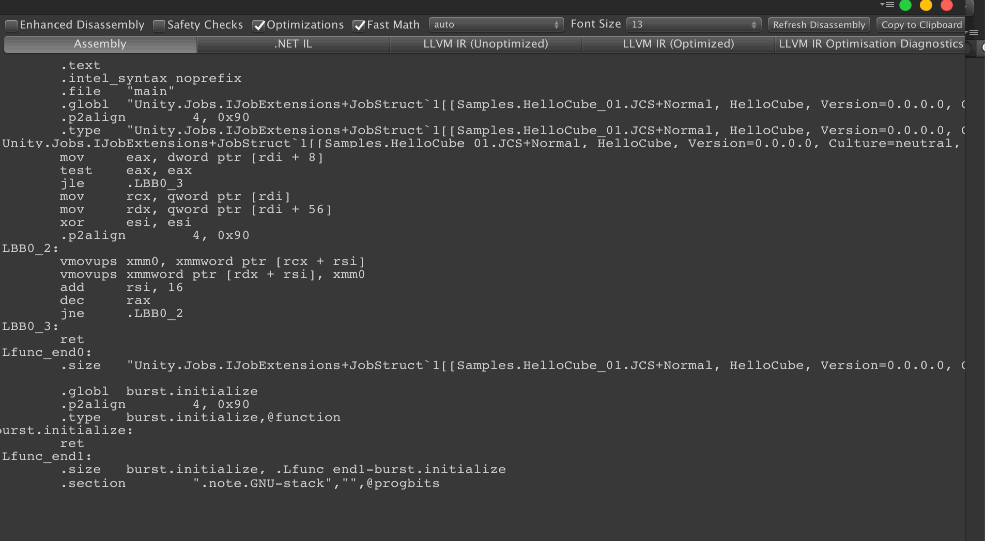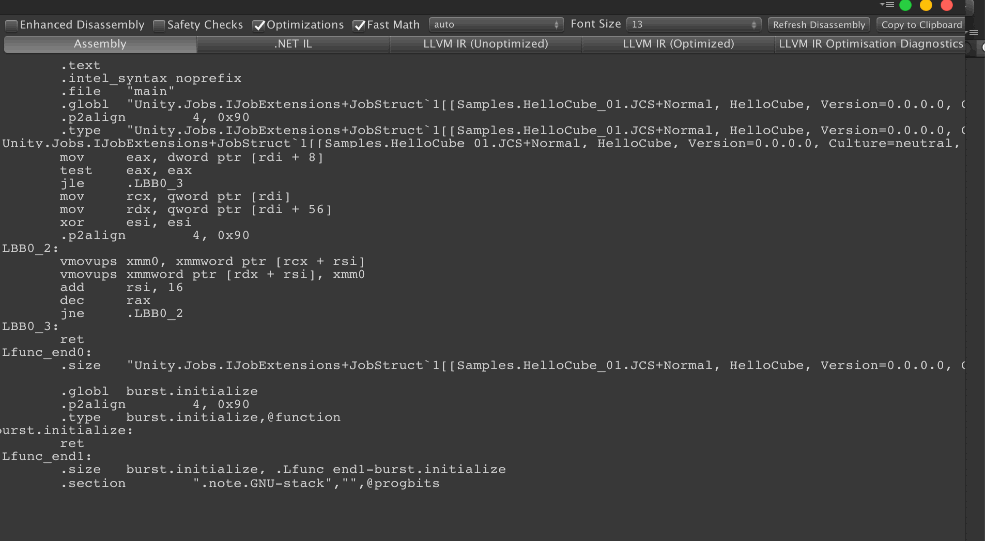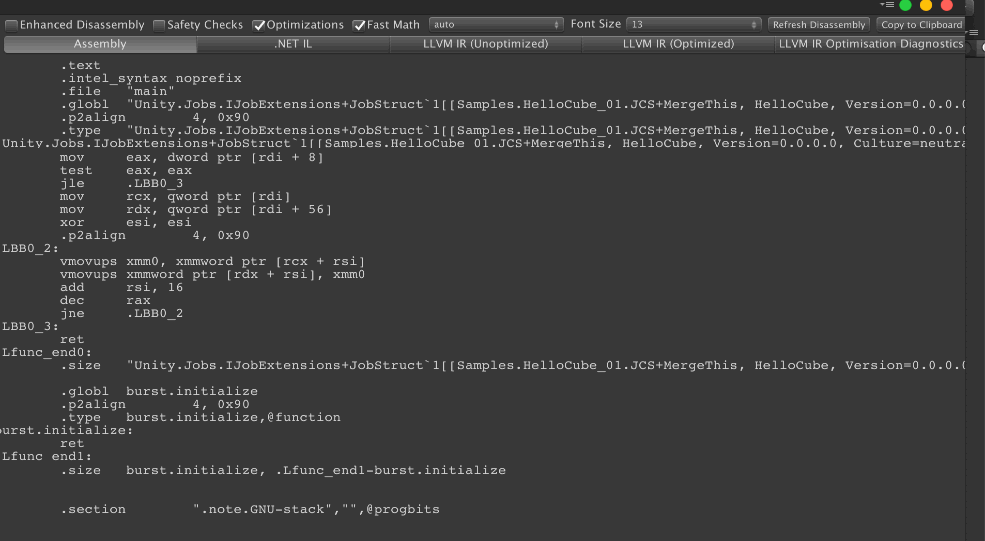
You get exactly the same assembly! Because the job is a copy, it only cares if it could use the xmm or not. 4 float has the same size and assembly compatibility as one float4. Note that because the job is a simple copy that the comparison is easy. If we do calculate on each field it would get more complex. But in this section, we focus on what could trigger xmm and ymm usage. (More in the Mathematics section!)
xmm ymm smartness test
We now know Unity could understand to merge individual fields to some extent (for copy). If your struct is instead this :
public struct Arrangement
{
public float a;
public float b;
public float c;
public float d;
public float e;
public float f;
public float g;
public float h;
}
Too lazy to paste assembly but basically you will get ymm instead of xmm. ( ymm is 256 bit = 8x float/int) You just doubled the work for the same performance! Nice!
How about
public struct Arrangement
{
public float a;
public float b;
public float c;
public float d;
public float e;
public float f;
// public float g;
// public float h;
}
(Irrelevant section omitted)
mov rdx, qword ptr [rdi]
mov rsi, qword ptr [rdi + 56]
vmovups xmm0, xmmword ptr [rdx + rcx - 20] # <--- 4 floats
mov rdx, qword ptr [rdx + rcx - 4] # <--- 2 floats
vmovups xmmword ptr [rsi + rcx - 20], xmm0
mov qword ptr [rsi + rcx - 4], rdx
Still good! It uses xmm once for 128 bit (4 float) and then use normal mov for quad word, because my architecture is 64 bit, rdx is able to hold 2 float.
If you uncomment public float g, it would do xmm + quad word + single float.
And also because vmovups command does not compute anything, it doesn't care about the underlying data type. So even if your struct is like this :
public struct Arrangement
{
public float a;
public int w;
public float b;
public int x;
public float c;
public int y;
public float d;
public int z;
}
It still results in a single ymm movement. Turns out, int could be counted as "scalar" the same as float. (And so the suffix s is usable for both)
Struct arrangement test
In this subsection we will try to bully Burst. Continued from the last section, how about this? double is 2 times the size of float, therefore I comment 2 float out and replace with that.
public struct Arrangement
{
public float a;
public int w;
public float b;
public int x;
public double yeah;
//public float c;
public int y;
//public float d;
public int z;
}
mov rdx, qword ptr [rdi]
mov rsi, qword ptr [rdi + 56]
vmovups ymm0, ymmword ptr [rdx + rcx - 28]
vmovups ymmword ptr [rsi + rcx - 28], ymm0
Still results in a single and neat ymm! Even if it is double, since we are not computing anything the s suffix of vmovups is still used to do all the work. Damn! Then,
public struct Arrangement
{
public float a;
public int w;
public float b;
public double takeThat; // <--- moved up
public int x;
//public float c;
public int y;
//public float d;
public int z;
}
mov rdx, qword ptr [rdi]
mov rsi, qword ptr [rdi + 56]
vmovss xmm0, dword ptr [rdx + rax]
mov r8d, dword ptr [rdx + rax + 4]
vmovss xmm1, dword ptr [rdx + rax + 8]
vmovsd xmm2, qword ptr [rdx + rax + 16]
mov r9d, dword ptr [rdx + rax + 24]
mov rdx, qword ptr [rdx + rax + 28]
mov qword ptr [rsi + rax + 28], rdx
mov dword ptr [rsi + rax + 24], r9d
vmovsd qword ptr [rsi + rax + 16], xmm2
vmovss dword ptr [rsi + rax + 8], xmm1
mov dword ptr [rsi + rax + 4], r8d
vmovss dword ptr [rsi + rax], xmm0
Haha! Finally you broke! The thing is double 's size is an outlier. When you place double at that position (following float int float ) Burst is kinda looking for that 4th 32 bit sized variable in order to complete the xmm usage. In this case it tries to broken down the copy to several pieces. You even got d suffix command to handle the double variable specifically.
So in the case of this simple struct copy, if you are tasked from your boss to create an IComponentData of following data what is the best way to organize your fields?
- One
floatfor overall game completion percentage. - 2
intfor currencies - 3
shortfor STR AGI INT floatfor each stage indication the highscore in percentage how far you went for 4 stages.
Doing that literally as your boss says would be :
public struct PlayerData: IComponentData
{
//Commented number indicates where the variable starts in memory.
public float overallCompletion; // 0
public int money; // 4
public int gem; // 8
public short strength; //12
public short agility; //14
public short intelligence; //16
public float stage1Completion; //20 (not 18!)
public float stage2Completion; //24
public float stage3Completion; //28
public float stage4Completion; //32
}
With a simple copy job (Ok I know you wouldn't want to copy tons of player data but it is just an example) the resulting assembly is :
mov rdx, qword ptr [rdi] # prepare source
mov rsi, qword ptr [rdi + 56] # prepare destination
vmovss xmm0, dword ptr [rdx + rax] # completion as double word (32)
mov r8, qword ptr [rdx + rax + 4] # money + gem as 1 quadword (32+32)
movzx r9d, word ptr [rdx + rax + 12] # str as one word (16)
mov r10d, dword ptr [rdx + rax + 14] # agi + int as double word (16+16)
vmovups xmm1, xmmword ptr [rdx + rax + 20] # stage 1 2 3 4 (32+32+32+32) all to xmm1 (128)
mov dword ptr [rsi + rax + 14], r10d # put in place
mov word ptr [rsi + rax + 12], r9w # put in place
mov qword ptr [rsi + rax + 4], r8 # put in place
vmovss dword ptr [rsi + rax], xmm0 # xmm0 put in place
vmovups xmmword ptr [rsi + rax + 20], xmm1 # xmm1 put in place
- the
dsuffix of register liker9dis indicating it is using just the lower double word of the register. My architecture is 64 bit, so the double word suffix indicates I am using only lower 32 bits part.) vmovsseven though it uses the bigxmmas the destination, it is moving just a little 32 bitoverallCompletionout of all available 128 bit space. The command that moves many values is instead something likevmovupsyou see on the stage completion 4floatmovement toxmm1.movzxthezis zero extension. The lower halfr9dis 32 bit in size but we are moving ashort, so we want to fill the remaining space with zeroes. There is no need for agility and intelligence since it fills all of the lower half.stage1Completionis not immediately afterintelligence(20 rather than 18). Because in C# each field are aligned by default to the size of itself. Thefloattype can therefore be in place like 0, 4, 8, 12, 16, 20, 24 , ... You see 18 is not a valid place to start.
Knowing these, what you could do to make it better? Naively, I will try to deal with these "weird" size by just add some dummy variables. (It's your boss's fault for not adding dexterity to the stats)
public struct PlayerData : IComponentData
{
public float overallCompletion;
public int money;
public int gem;
public int foo; // so that float+float+float+int completes xmm size
public short strength;
public short agility;
public short intelligence;
public short bar; // so that short*4 completes half of xmm size
public float stage1Completion; //these are already looking nice
public float stage2Completion;
public float stage3Completion;
public float stage4Completion;
}
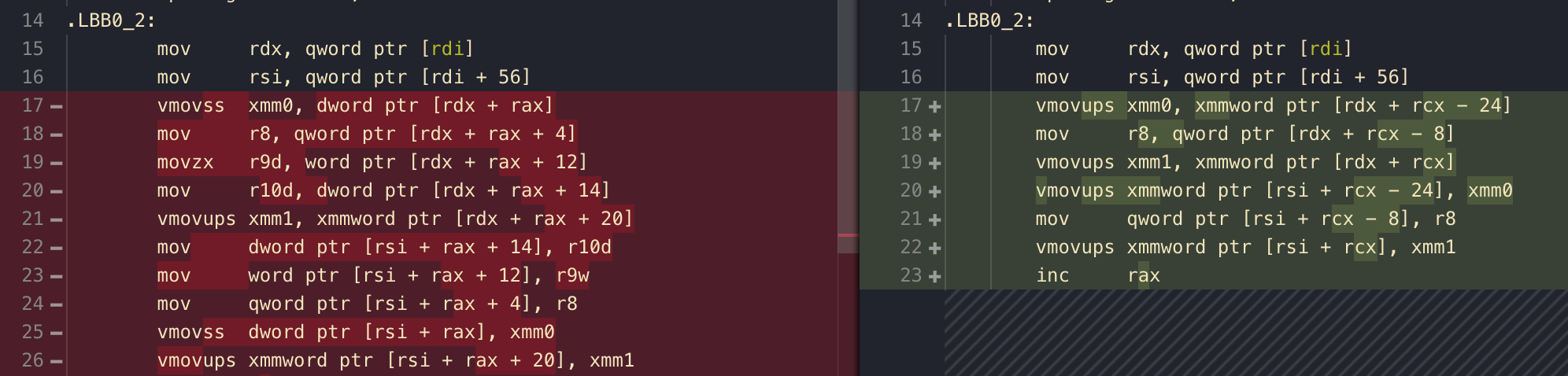
Immediately you could see an improvement! Instead of 5 combo of vmovss + mov + movzx + mov + vmovups we are now at 3 combo of vmovups + mov + vmovups. Not only that, 2 of them fully utilized xmm register unlike the vmovss. (However the C# code is now ugly)
Don't mind the rcx that appears instead of rax, they seems to just switch place. And it seems to be doing some gymnastics by starting that at 24 then minus back to get the head of struct. This is so that the "0" starts at exactly stage1Completion. I am not sure of its intention, but it could be a good thing with something something aligned. (However the a variant was not used)
So what do we have now? vmovups + mov + vmovups. The vmovups handles float + 3 int. (one dummy) The mov is using r8 which on 64 bit machine could handle 2 int, or in this case 4 short. (one dummy) Finally that delicious 4 float vmovups the same as before.
Hate dummy variable? You could use [StructLayout(LayoutKind.Explicit)] to offset your fields to get exactly the same improved assembly. Like this :
[StructLayout(LayoutKind.Explicit)]
public struct PlayerData : IComponentData
{
[FieldOffset(0)] public float overallCompletion;
[FieldOffset(4)] public int money;
[FieldOffset(8)] public int gem;
[FieldOffset(12 + 4)] public short strength; //Adds imaginary int
[FieldOffset(18)] public short agility;
[FieldOffset(20)] public short intelligence;
[FieldOffset(22 + 2)] public float stage1Completion; //Adds imaginary short
[FieldOffset(28)] public float stage2Completion;
[FieldOffset(32)] public float stage3Completion;
[FieldOffset(36)] public float stage4Completion;
}
Your struct ends at byte 40. It is an equivalent of 10 int. Remember that xmm is 128 bit and therefore able to do 4 int of work. For ymm, 256 bit, it could do 8 int of work. What if we try to make the size suitable for ymm? 8 int are 8 * 4 = 32 bytes. We just went over that.. the next threshold is as high as byte 64.
Let's try to pad so that the last stage4Completion starts at byte 60, so it ends at exactly 64 and see what happens.
[StructLayout(LayoutKind.Explicit)]
public struct PlayerData : IComponentData
{
[FieldOffset(0)] public float overallCompletion;
[FieldOffset(4)] public int money;
[FieldOffset(8)] public int gem;
[FieldOffset(12 + 4)] public short strength;
[FieldOffset(18)] public short agility;
[FieldOffset(20)] public short intelligence;
[FieldOffset(48)] public float stage1Completion;
[FieldOffset(52)] public float stage2Completion;
[FieldOffset(56)] public float stage3Completion;
[FieldOffset(60)] public float stage4Completion;
}
mov rdx, qword ptr [rdi]
mov rsi, qword ptr [rdi + 56]
# copy out part
vmovups xmm0, xmmword ptr [rdx + rcx - 48] #same float + 3 ints (one empty)
mov r8d, dword ptr [rdx + rcx - 32] #Just 2 shorts bc using r8d
movzx r9d, word ptr [rdx + rcx - 28] #More 2 shorts (one ???) bc using r9d
mov r10d, dword ptr [rdx + rcx - 26] #int sized ??? that must be copied
movzx r11d, word ptr [rdx + rcx - 22] #leftover fragment of ???
vmovups xmm1, xmmword ptr [rdx + rcx - 20] #tons of ???
mov ebx, dword ptr [rdx + rcx - 4] #???
vmovups xmm2, xmmword ptr [rdx + rcx] #final 4 floats
# put back part
vmovups xmmword ptr [rsi + rcx - 48], xmm0
mov dword ptr [rsi + rcx - 32], r8d
mov word ptr [rsi + rcx - 28], r9w
mov dword ptr [rsi + rcx - 26], r10d
mov word ptr [rsi + rcx - 22], r11w
vmovups xmmword ptr [rsi + rcx - 20], xmm1
mov dword ptr [rsi + rcx - 4], ebx
vmovups xmmword ptr [rsi + rcx], xmm2
It didn't go as planned. This time the prior fields are literally bursted into little fields! Even if you use FieldOffset the assembly must still copy whatever sitting at that blank space. And with no typing information on those area, it seems Burst is not so smart and didn't do a single big ymm copy like I hope it would.
So it seems just like the case where a misplaced double could cause trouble for Burst, intentionally space things out too much just to hope for ymm is not such a good idea since Burst will now think about how to handle those spaces. Make space only if it is just a bit more to complete 4x32 bit or 8x32 bit should give you good result.
Enums with different underlying type
enum doesn't have to be an int. In C#, we can use a value as small as byte if it is not going to get over 256 kind of enums.
I have written a vectorizable job of going through a struct of 4 enums that is a byte each, to see if we can use 4 of them in place of a single int.
public enum Element : byte { None, Fire, Water, Thunder, Wood }
public struct MultipleElements
{
public Element e1;
public Element e2;
public Element e3;
public Element e4;
public byte Sum => (byte)((byte)e1 + (byte)e2 + (byte)e3 + (byte)e4);
}
[BurstCompile]
public struct EnumVectorizeJob : IJob
{
public NativeArray<MultipleElements> from;
public NativeArray<byte> to;
public void Execute()
{
for (int i = 0; i < from.Length; i++)
{
to[i] = (byte)(from[i].Sum * 555);
}
}
}
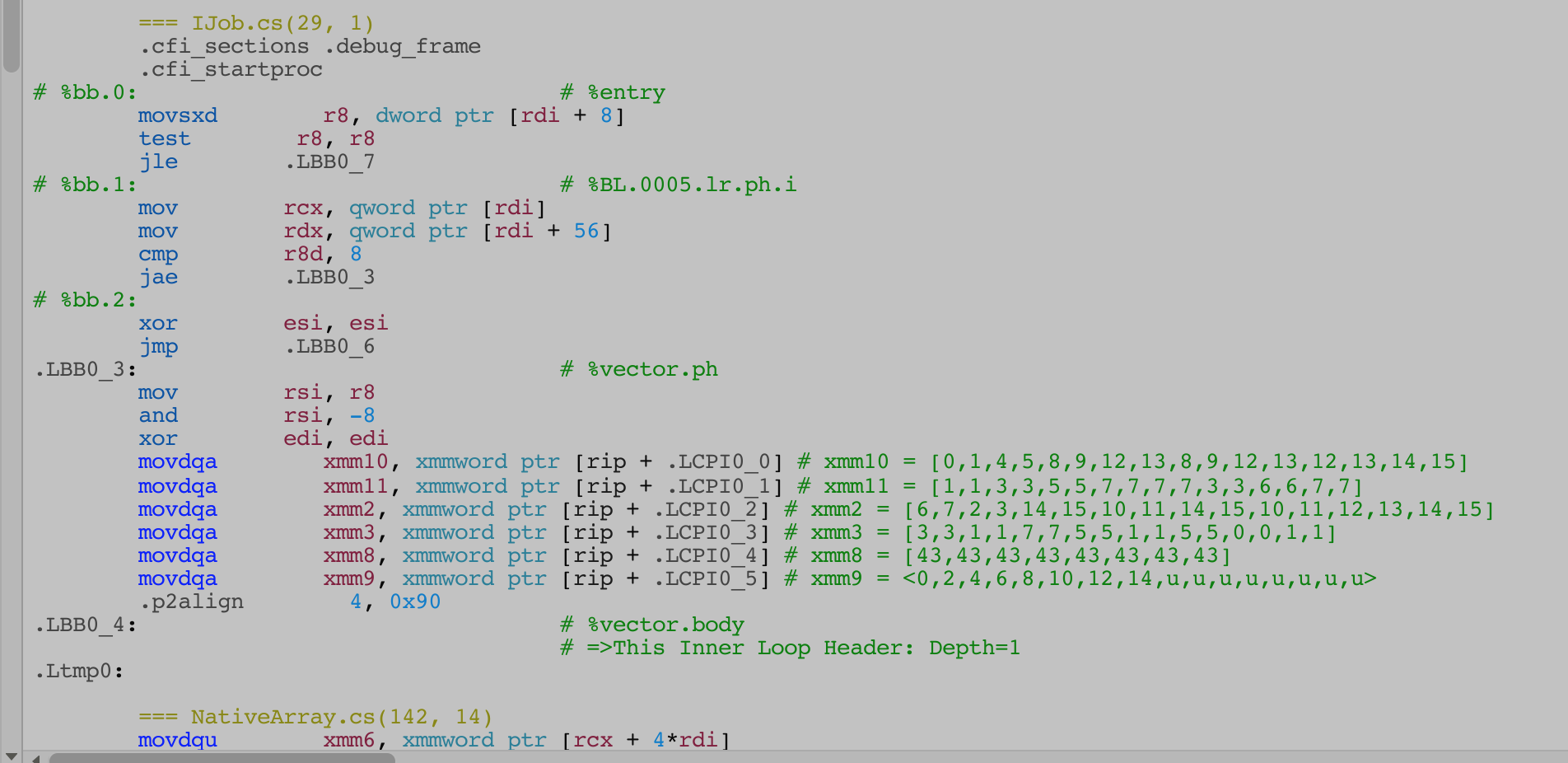
There are a lot more below, but roughly looking that we got some xmm registers going, it seems like byte on enum was effective. It is not like it would be padded into an int when composed in the struct.
In comparison, I try making the struct inefficient intentionally by removing one byte sized enum from it.
public enum Element : byte { None, Fire, Water, Thunder, Wood }
public struct MultipleElements
{
public Element e1;
public Element e2;
public Element e3;
//public Element e4;
public byte Sum => (byte)((byte)e1 + (byte)e2 + (byte)e3);// + (byte)e4);
}
[BurstCompile]
public struct EnumVectorizeJob : IJob
{
public NativeArray<MultipleElements> from;
public NativeArray<byte> to;
public void Execute()
{
for (int i = 0; i < from.Length; i++)
{
to[i] = (byte)(from[i].Sum * 555);
}
}
}
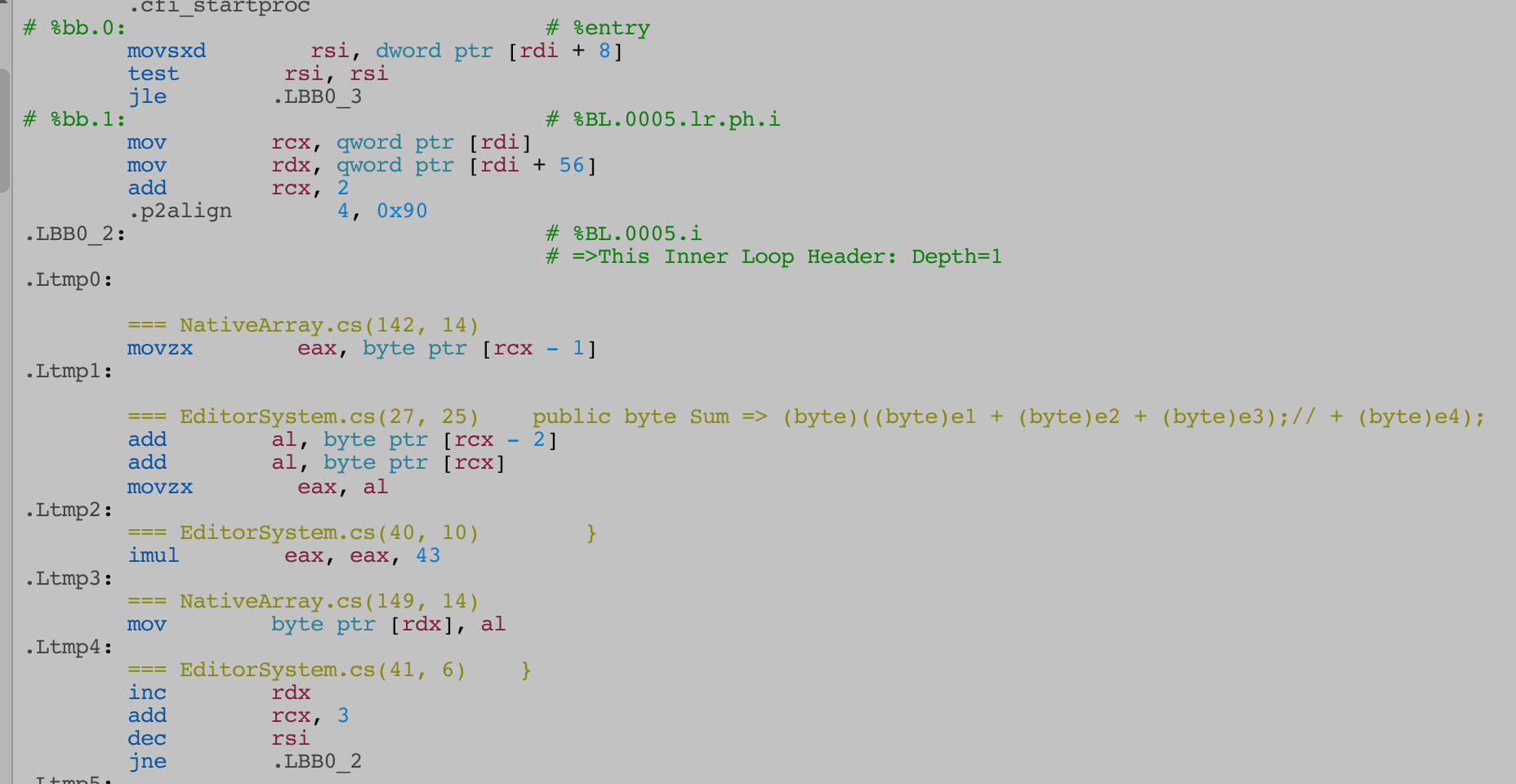
You see that just one byte removed throw off the vectorizer, it became a much simpler for loop one by one.
Therefore concluding that you should think about your enum's underlying type and think if it composed into a weird size or not. If you can't find other things to make it at least an int size, maybe you should keep that enum an int.
The only problem : byte, ushort etc. you are trying to save cache space with, are a pain to work with in C# since any math operation keep returning those to int. (Yet int vs int didn't become a long !) So you see type casting everywhere, but it maybe necessary to shrink down your component so you get more entities in one cache line read.
Lesson learned
- Try to make your same sized fields sit neatly in
xmmorymmsize to increase the chance of getting the good stuff. - Burst do not have neural network to understand your code so help it by arranging your
structneatly, with understanding about underlying available assembly commands in mind. What you do is probably more complex than this simple copy, but neatly is always better than not. - If your code path is very hot, it might worth trying to hack the struct for a bit and see if it helps Burst.
- Do not try to outsmart Burst too much or it might throw tantrum like what you just saw. Use the Burst inspector when in doubt.
LLVM
This is not specific to Burst. Most compilers will optimize some specific "moves". Burst is using LLVM, knowing some routine that triggers optimization in LLVM might help programming better code. You could try to test around to observe what Burst use from the total of tools in LLVM here : http://llvm.org/docs/Passes.html#transform-passes
Google for "LVVM optimization" for further reading.
Integer multiplication with power of two
- If you multiply something by 16 it would results in shift left by 4 bits instead. You don't need to say
<< 4explicitly, keep the code readable. What's needed is that you are aware that 16 or any power of two are special value and use it in your algorithm. - If you multiply something by 2 it would be added with itself instead. I suspect this maybe even faster than shifting bits.
You might be thinking about optimizing something like *33 with *32 + itself instead. So I have the following test :
[BurstCompile]
public struct StraightForward : IJob
{
public NativeArray<int> source;
public NativeArray<int> destination;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
var foo = source[i];
foo = foo * 33;
destination[i] = foo;
}
}
}
[BurstCompile]
public struct Nitpicky : IJob
{
public NativeArray<int> source;
public NativeArray<int> destination;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
var foo = source[i];
foo = (foo * 32) + foo;
destination[i] = foo;
}
}
}
Both produce the same assembly. The solution it used is multiply by 33 rather than shift and add one more. So don't be nitpicky and just write readable code!
Floating point division
Is just turned into a multiplication by pre-flipping the divide.
Integer division
We will try a vectorized integer division with simple number 2, 3, 4, 5 !
[BurstCompile]
public struct Two : IJob
{
public NativeArray<int> source;
public NativeArray<int> destination;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
var foo = source[i];
foo = foo / 2;
destination[i] = foo;
}
}
}
[BurstCompile]
public struct Three : IJob
{
public NativeArray<int> source;
public NativeArray<int> destination;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
var foo = source[i];
foo = foo / 3;
destination[i] = foo;
}
}
}
[BurstCompile]
public struct Four : IJob
{
public NativeArray<int> source;
public NativeArray<int> destination;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
var foo = source[i];
foo = foo / 4;
destination[i] = foo;
}
}
}
[BurstCompile]
public struct Five : IJob
{
public NativeArray<int> source;
public NativeArray<int> destination;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
var foo = source[i];
foo = foo / 5;
destination[i] = foo;
}
}
}
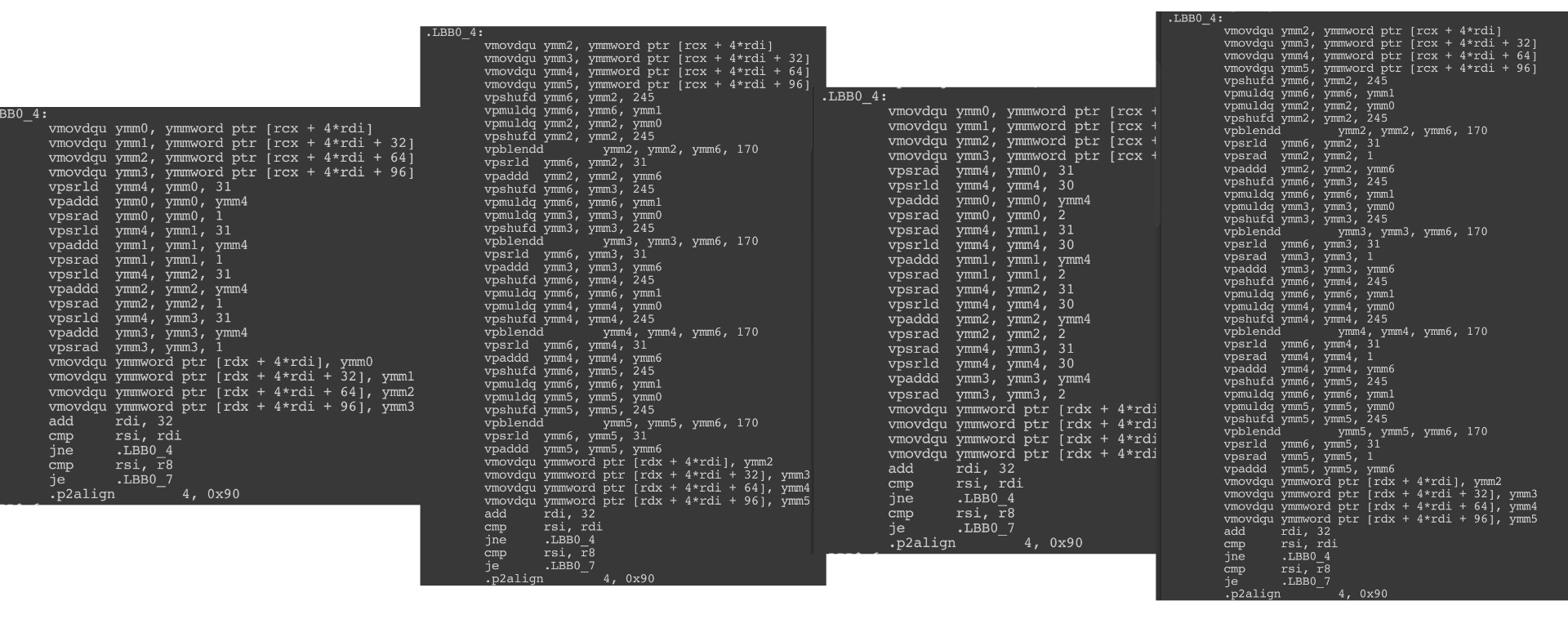
It looks quite different! You see it is trying to shift around by various patterns and multiplying instead of really dividing, while still using ymm. (There is no divide instruction, actually) I don't want to figure out what is it doing to finally divide integer for us.
(The float SIMD division looks much shorter too, since it is just a multiplication. However I don't know how many clock cycles of those will compare to these integer division.)
Also I observe that power of two division looks "neater", but not as neat as I thought. Why? The reason is because...
Power of two integer division and the sign bit
*32 might be correctly turned into << 4, but division /32 is an another story! It is not as simple as flipping the shift to >> 4 because now we have to deal with sign bit. If sign bit moves back to the left it would spill into the real value. (This integer layout is called two's complement)
And so, division with power of two is able to be optimized into bit shifting only if you are using unsigned integer to ensure there is no sign bit.
What if we change the prior 4 jobs to uint instead of int?
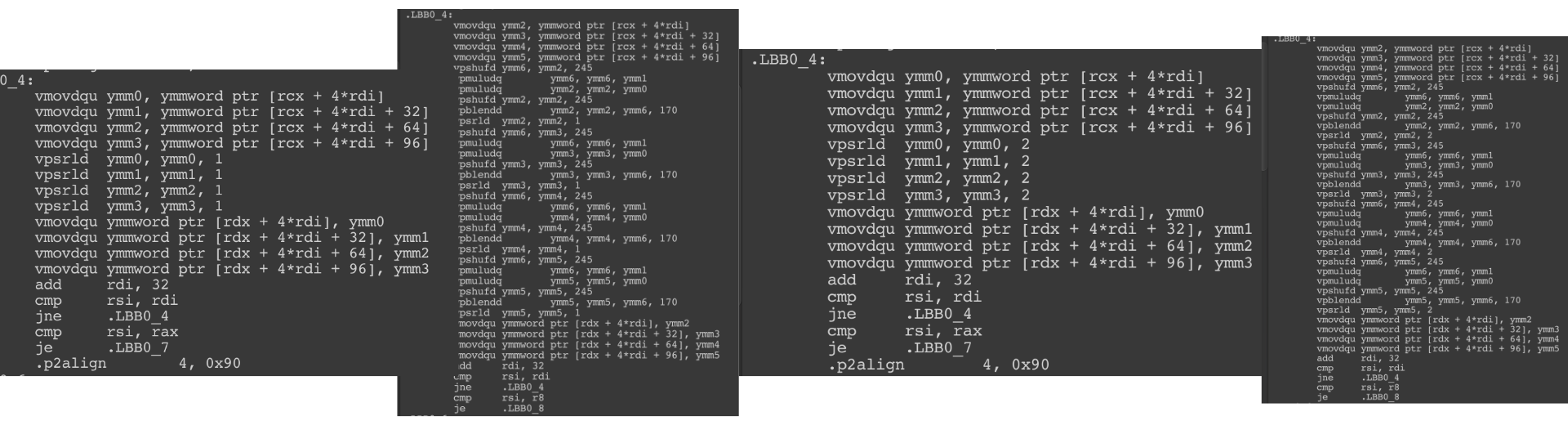
There we go! The divide by 3 and 5 is still looking involved, but the 2 and 4 are now just as simple as bit shifting to the left by 1 and 2. This is where you have to be aware of the underlying optimization why shifting left is problematic and how you could help Burst. Should you begin using uint for "obviously not making sense if negative" int now? Personally, I am lazy and just use int everywhere. But maybe good to know there are cases that uint matters (more than number limit, and ushort give you as much as 60000 maybe that's plenty).
Unity.Mathematics and SLEEF
In general you should use things from Unity.Mathematics as much as possible. But for educational purpose let's compare assembly code to see what happens when you don't.
public struct S1
{
public float x;
public float y;
public float z;
public float w;
}
public struct S2
{
public float4 vect;
}
[BurstCompile]
public struct Separated : IJob
{
public NativeArray<S1> source;
public NativeArray<S1> destination;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
var foo = source[i];
foo.y += 555;
destination[i] = foo;
}
}
}
[BurstCompile]
public struct Mathematics : IJob
{
public NativeArray<S2> source;
public NativeArray<S2> destination;
public void Execute()
{
for(int i = 0 ; i < source.Length; i++)
{
var foo = source[i];
foo.vect.y += 555;
destination[i] = foo;
}
}
}
For just a single field operation like this, you get exactly the same assembly. There is no other magic it could do, you are using float4 like 4 float. Everything is just an offset from one anchor point, the array head's pointer, after all.
In this next task, we could deliberately use Unity.Mathematics by doing the addition like this, so it became "whole vector" operation.
[BurstCompile]
public struct Mathematics : IJob
{
public NativeArray<S2> source;
public NativeArray<S2> destination;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
var foo = source[i];
foo.vect += new float4(0, 555, 0, 0);
destination[i] = foo;
}
}
}
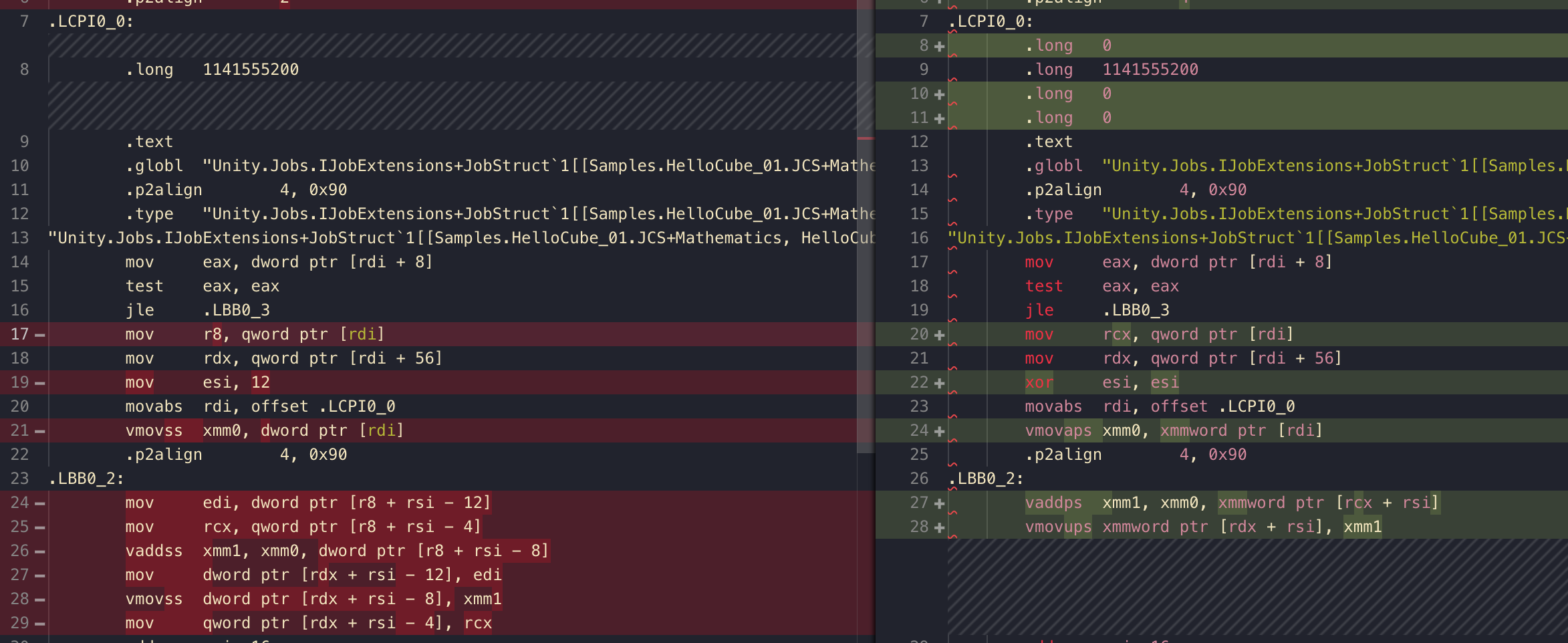
Some of you might be allergic to the word new, but see that 1141555200 should be 555 in floating point representation (?). You can see that it now became (0, 1141555200, 0, 0) like we do in the code. And it is like a constant defined directly in the assembly, the new do no harm as long as it is a simple struct like this and it could be load from as a whole by offset operand.
(I am not sure if this is the case with normal C# or not, I went to a website that gives me JIT assembly, and new the struct seems to produce a code that construct the struct naively by putting data into memory one by one.)
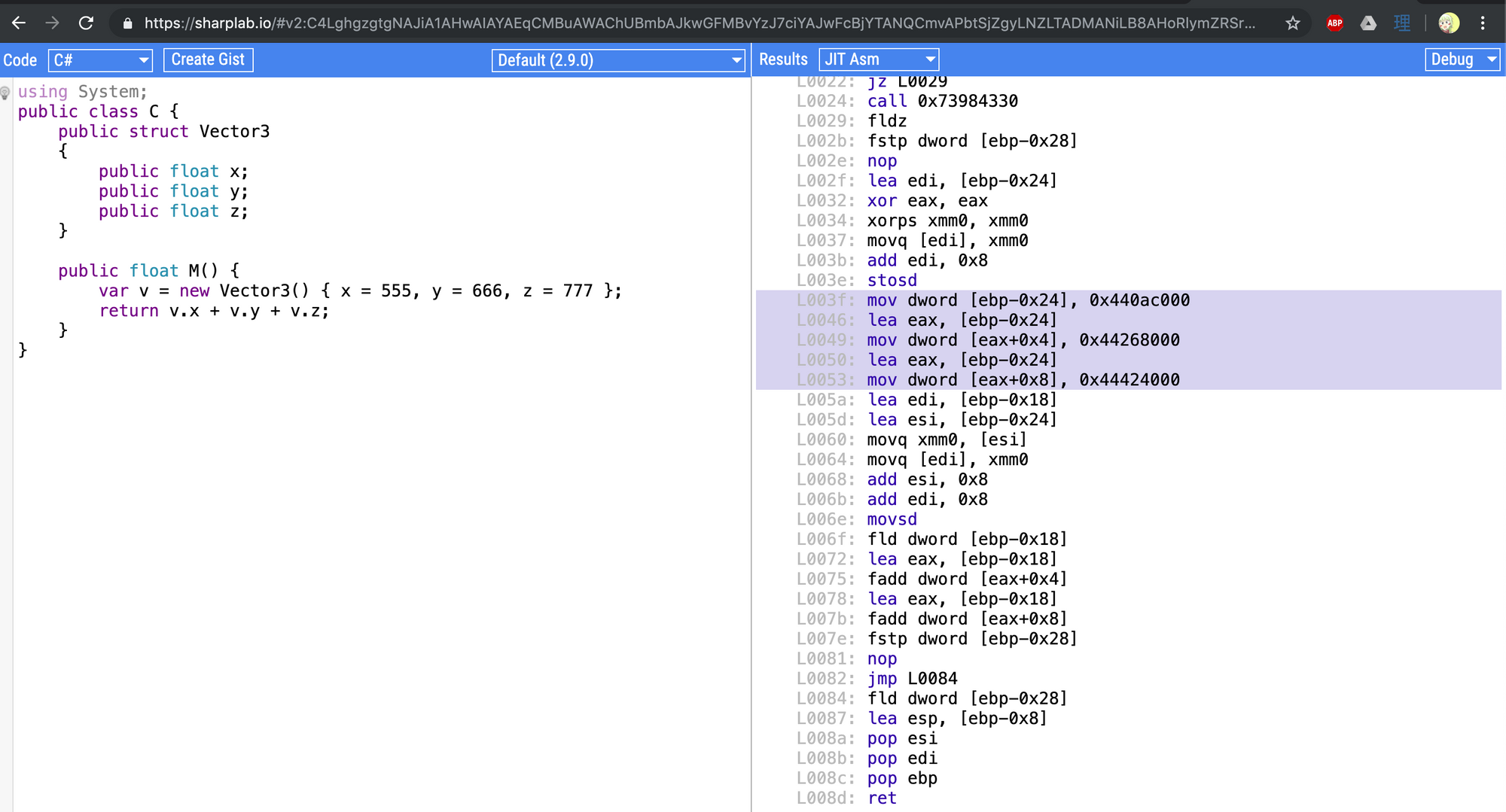
That memory is vmovaps onto xmm0 then thanks to vaddps, all are added at the same time to the destination xmm1. If other values weren't 0 this would obviously be faster. In this case I think it is mostly a draw.
The talk

This is a relevant section of the talk from Unite LA 2018 on this topic :
Is float3 that much worse than float4 ?
From the previous example, we just change to float3 and adding (0, 555, 0) instead of (0, 555, 0, 0) producing the same behaviour. This is the diff :
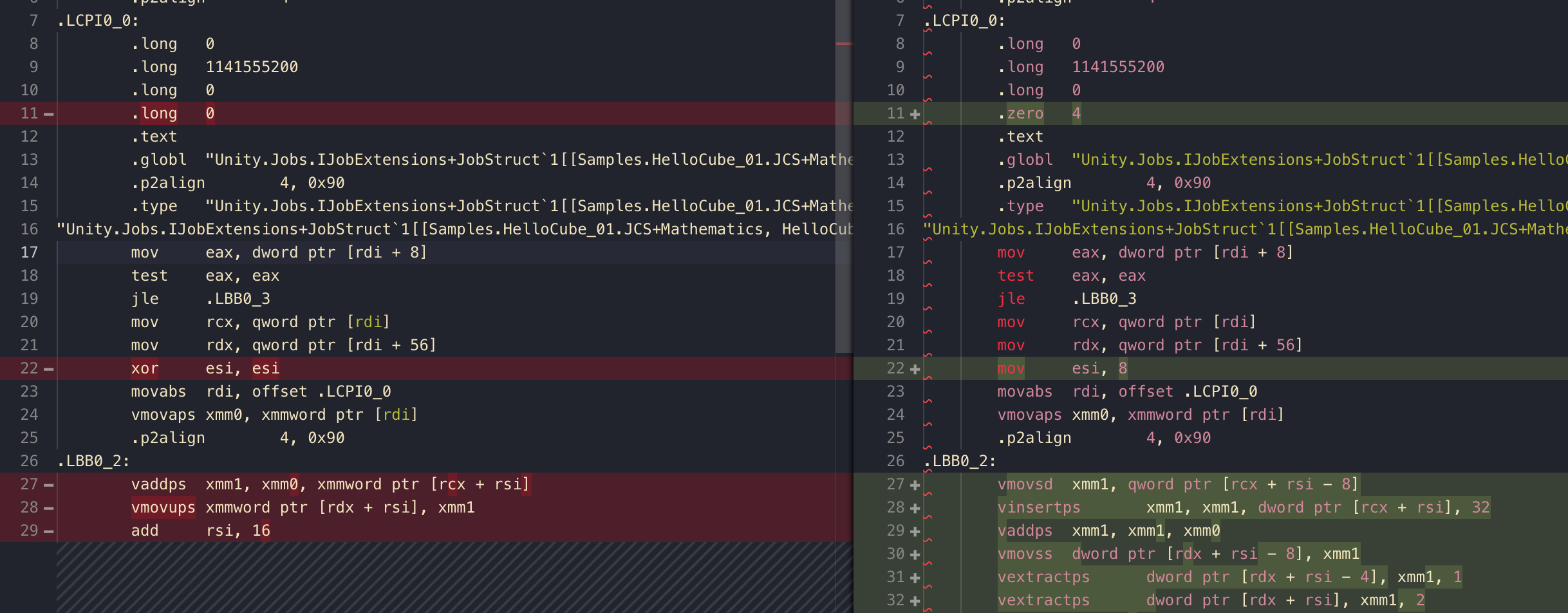
Some interesting things happening here!
- Unity is trying hard to be able to do that
vaddps xmm1, xmm1, xmm0line again. Howeverxmmcould hold 4float. What to do when we are usingfloat3? - At the top you see Unity adds back
.zero 4so that even withfloat3, the size of.LCPI0_0is usable withxmmrelated command! The whole thing is inxmm0 esiis the same thing asrsibut just the lower half. The value is pre set to 8. This 8 is related to z component, which will help us frankenstein the odd-shapedfloat3for 128-bit sized calculation.- We see a command like
vmovsdwithdsuffix for double precision, even though we are not using any double precision variable. Actually this is a trick becausevmovsswith this memory location would have moved only single value x of ourfloat3, but since we saysdit also get the y component offloat3along with it. (I spent 15 minutes figuring that out!!) vinsertpsis for that final z component offloat3. It can pinpoint and grab any little floating point offset from any memory (if you put memory as the 2nd operand), and insert into the destination without destroying other values, plus some useful masking feature.
Thedword ptr [rcx + rsi]is +8 from the currently operatingfloat3which we arrive at the z field. (esiis the same thing asrsiremember)
Nummer32of the 8-bit immediate operand encode several options for this command. The value is0010000in base-2, and that bit 5:4 happen to be something called Count_D, saying the target position on the destination to place the value (and not disturb others) It has 4 possible value and right now it is "2" (10) that is exactly at the z component.
According to the Intel manual , in the case of memory source (SRC != REG) this command immediately grab one float at the memory area specified. If you use a register rather than a memory, you could encode the bit 7:6 as where to pick from that register too.

- Wow! So much for preparing the
xmm1to have our x y z! (Notice that the 4th element ofxmm1maybe some junk we don't care.) Finally we can do that sweetvaddps. - The final
vmovssvextractpsvextractpsare all single value commands. The first one move 1 field loated onxmm1by default (so we get the resulting x), the 2nd and 3rd are used to get the value from exact offset. (y and z) And so withfloat3, the save back has to be "handpicked" one by one to the destination, fearing that if we do something like in thefloat4case the junk would spill into the x component of the nextfloat3in ourNativeArray.
Um... so tl;dr, float3 is considerably more involved than float4! You may have OCD from using float4 instead of float3 where the w component isn't really needed, but that's one way you could help Burst.
float2?
I am not going to step through this ever again. In summary it is almost the same, except you don't see vinsertps to hack in that z component, and there is only one vextractps at the end. Voila you get a float2 addition!
half
You can use half for half precision float. It take the same space as ushort. It could mean you can get double the float in one cache line read!
I didn't debug half's generated code yet, it looks like an easy way to speed up your code. But don't assume so without profiling. Personally I don't want to mess with them just yet when there is no mention in the docs at all.
Take this simple example :
[BurstCompile]
private struct HalfJob : IJob
{
public NativeArray<half> halfs1;
public NativeArray<half> halfs2;
public NativeArray<half> halfsAnswer;
public void Execute()
{
for (int i = 0; i < halfs1.Length; i++)
{
halfsAnswer[i] = (half) (halfs1[i] * halfs2[i]);
}
}
}
[BurstCompile]
private struct FloatJob : IJob
{
public NativeArray<float> float1;
public NativeArray<float> float2;
public NativeArray<float> floatAnswer;
public void Execute()
{
for (int i = 0; i < float1.Length; i++)
{
floatAnswer[i] = (float1[i] * float2[i]);
}
}
}The assembly generated is massive on taking data out and store back because of bit shifting required to use ushort space as floating point, before coming to the same mulps that is used for float.
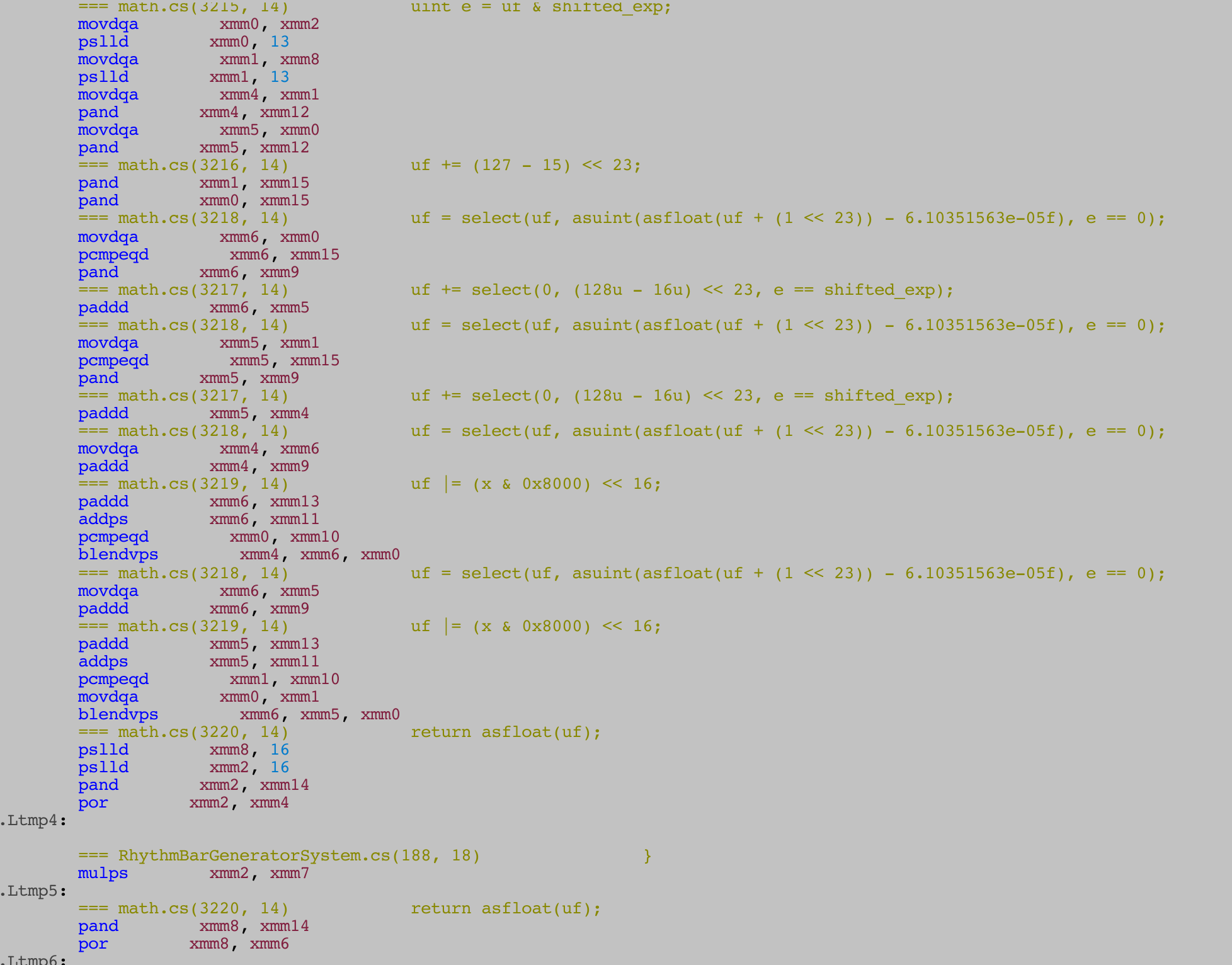

I cannot provide verdict but looking from assembly I would stick to float. Then could we reason the same way that we should not use short but just keep using int? I think we need to weight the cost wisely since smaller size do result in better cache line read since we could get more of them. This preparation assembly maybe worth the cache line boost we get.
Then only answer is please profile your game!
Assembly replacement
For some Unity.Mathematics commands, they have been preprogrammed to be replaced directly with assemblies that they think it is better than letting the compiler deal with the math in a more general purpose way.
To see this, let's test it out on the dot product command between 2 float4. The dot is just each element multiplying with each other and produce summation of them as float. It is defined like this in the library :
/// <summary>Returns the dot product of two float4 vectors.</summary>
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static float dot(float4 x, float4 y) { return x.x * y.x + x.y * y.y + x.z * y.z + x.w * y.w; }
[MethodImpl(MethodImplOptions.AggressiveInlining)] just tell C# to make sure to inline it. Remember that naively we will require 4 multiplies and 3 additions. The compiler could do something about that, but Burst goes even beyond by replacing the entire line with a premade assembly. Let's see :
[BurstCompile]
public struct DotManually : IJob
{
public NativeArray<float4> a;
public NativeArray<float4> b;
public NativeArray<float> result;
public void Execute()
{
for (int i = 0; i < result.Length; i++)
{
var x = a[i];
var y = b[i];
result[i] = x.x * y.x + x.y * y.y + x.z * y.z + x.w * y.w;
}
}
}
[BurstCompile]
public struct Dot : IJob
{
public NativeArray<float4> a;
public NativeArray<float4> b;
public NativeArray<float> result;
public void Execute()
{
for (int i = 0; i < result.Length; i++)
{
result[i] = math.dot(a[i], b[i]);
}
}
}
You see the DotManually job, it is just trying to inline by hand instead of letting C# do the AggressiveInlining. In normal case, the math.dot should be inlined the same way as I do and in turn produces exactly the same assembly.
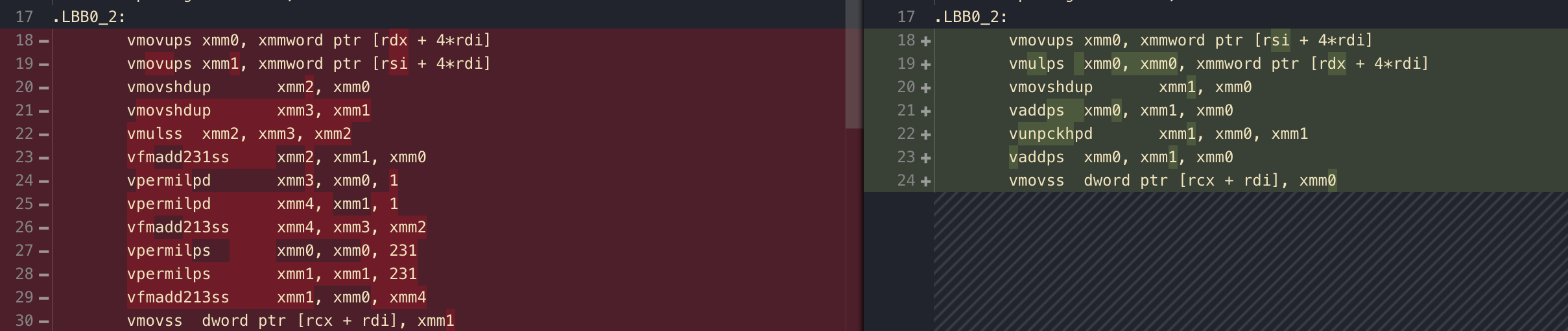
But somehow they produced different assemblies! Isn't that interesting?
Starting from the left side where I dot product by hand. This is already quite cutting edge, as not only you see tons of xmm being used, but a rare command like vfmadd are there. FMA is not Full Metal Alchemist but rather fused multiply-add, it could multiply and add faster than 2 separated operations. It is added in AVX2 and later update which is considered quite a new addition, specifically because many math operations need to multiply and add, like this dot product. Together with permutation command vpermilps it managed to use FMA 3 times and multiply 1 time to get us the dot product. (Rather than 4 multiplies + 3 additions for naive by-hand dot product)
But look at the right side's Burst handmade assembly. Just 1 xmm multiply and 2 xmm add! How can that be? Not even a single FMA command used.
This gymnastic even defy the "traditional assembly ceremony", that is "pulling the variable out" for work (seen as 2x vmovups on the left), work, and then finally "store back" the calculation (seen as vmovss on both sides). You see the right side there is only one vmovups to bring one float4 to the xmm0 work table. The other one still stays in memory, and is going to be worked out from memory since assembly language allows 1 memory operand per command.
Custom premade assembly like this allow us to make this exception that may not be safe for all cases, but we know it is just a dot product that it should be safe.
The first vmulps take care of 4 parallel multiply needed for the dot product in one go, also direct from memory to xmm0. (This is why we could save the beginning ceremony) What's left is too add together the 4 multiplied values in each float in our xmm0.
But there is no command to add itself based on 4 little bits of itself. I am not going to step through this, but it utilizes help from xmm1 by duplicating some xmm0 elements to it, add, then unpack/interleave one more time ( vunpckhpd, no interest to learn how that works) then add again. Getting a result of 2 adds down from 3 adds of naive dot product algorithm.
In short, typing out the math vs. just use math.__ is not the same. Unity knows "this is a dot product" in the latter case while dot product by hand was seen as "just some maths".
The extraction property
There is this hidden feature on your float2/3/4. If you try to for example f4.xz you will really get a float2 of x and z from the float4, even though you don't see it pops up in the intellisense but it works! This is possible because Unity put [System.ComponentModel.EditorBrowsable(System.ComponentModel.EditorBrowsableState.Never)] in the code, or else you will see tons of them because there are too many possible combinations. (duplicates like .xxyy .xxxx is also possible)
But this is just doing new float4 for you, as far as I tried it doesn't make a different assembly, at least for now? (March 30, 2019)
The shuffle method
One really hip method is math.shuffle where you could give it 2 vectors and then could specify the product to be a combination of any elements from both. For example if you have a certain strange requirement to write a new value that came from w z of destination and y x of source, arranged into a new float4.
[BurstCompile]
public struct Shuffle : IJob
{
public NativeArray<float4> source;
public NativeArray<float4> destination;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
destination[i] = math.shuffle(source[i], destination[i],
math.ShuffleComponent.RightW,
math.ShuffleComponent.RightZ,
math.ShuffleComponent.LeftY,
math.ShuffleComponent.LeftX
);
}
}
}
[BurstCompile]
public struct Boring : IJob
{
public NativeArray<float4> source;
public NativeArray<float4> destination;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
destination[i] = new float4(destination[i].w, destination[i].z, source[i].y, source[i].x);
}
}
}
...but both case produces the same assembly. However do note that the existence of ShuffleComponent enum could potentially aid your logic with switch case. switch case usually get fast assembly if the choices are enum rather than something like int. (You get a jump table of sorts, instead of tons of comparison)
Matrix operation
There are whole lot more to play with if you managed to use something like float4x4 to do work with an another float4x4. But I am not strong in matrix operation, I coudn't think of some way to creatively use something like dot, cross product, or inverse outside of computer graphics stuff.
But if you could find some shortcut that could use matrix operation, the generated assembly might be crazy good.
SLEEF
The replaced assemblies came from an open source library named SLEEF, as you might seen from the video prior. https://sleef.org/ One of the author came from the same university I went for my master degree at Japan!
It is a library that implement math functions (such as tan) that could vectorize and run on different target hardware without you changing the code. Because SIMD instructions vary per hardware, this library is trying to solve this portability problem.
One more thing is that it let you choose accuracy as well, which Burst expose it to C# with FloatPrecision attribute. See more : https://docs.unity3d.com/Packages/com.unity.burst@latest/
We should learn what SLEEF is doing exactly so we know our final code. But that's not for this article. (For example, if you know SLEEF use faster path if arguments to math function are under 15, you would be aware of speed gain if the angles are small.)
Lesson learned
- Use
Unity.Mathematicsas much as possible. - When hot code path optimization is needed, just trust this holy quote :
Note that for performance reasons, the 4 wide types (float4,int4...) should be preferred
Properties
C# properties are not evil. Especially if they are not "auto-implemented properties" but just accessing some fields. You may have heard properties = method call and thus must be avoided at all cost! Since method call must do some stack state restore push pop etc...
I don't know if this is the case of C# in general or because of Burst, but properties that returns a value do not equal to method call but get inlined into just a value.
In this imaginary situation we want to manage 6 skill cooldowns at once. Because we learned about SIMD potential of float4 the design is to minus the time to all of them. But it is difficult to know which field is for which skill being float4 like this, so I have created some properties to represent them.
public struct Cooldowns : IComponentData
{
private float4 cooldowns1;
private float4 cooldowns2;
public void ApplyTime(float time)
{
cooldowns1 -= time;
cooldowns2 -= time;
}
public float PileDriver => cooldowns1.x;
public float AdaptiveShield => cooldowns1.y;
public float GrappleHook => cooldowns1.z;
public float Minefield => cooldowns1.w;
public float BioticGrenade => cooldowns2.x;
public float SleepDart => cooldowns2.y;
}
[BurstCompile]
public struct CooldownJob : IJob
{
public NativeArray<Cooldowns> cooldowns;
public NativeArray<float> extract;
public float time;
public void Execute()
{
for (int i = 0; i < cooldowns.Length; i++)
{
var foo = cooldowns[i];
foo.ApplyTime(time);
cooldowns[i] = foo;
extract[i] = foo.PileDriver;
}
}
}
The generated code show that the SIMD minus works, and also using the property is as straightforward as offsetting a field from float4 directly. Even the ApplyTime struct method is not evil and got inlined here.
mov rdx, qword ptr [rdi]
vmovups xmm0, xmmword ptr [rdx + rax]
vmovups xmm1, xmmword ptr [rdx + rax + 16]
vbroadcastss xmm2, dword ptr [rdi + 112]
vsubps xmm0, xmm0, xmm2
vsubps xmm1, xmm1, xmm2
vmovups xmmword ptr [rdx + rax], xmm0
vmovups xmmword ptr [rdx + rax + 16], xmm1
mov rdx, qword ptr [rdi + 56] # <-- used the PileDriver property
If the property is auto-implemented, the backing field will count as a normal field. There is no other magic, just that you tends to forget to count them in when planning struct size...
Conditionals
In short, the assembly j-anything (branching command) should be avoided. The assembly command didn't actually run one by one but in pipeline.
Imagine you are doing add, first it pulls out some memory then it adds number. When it is adding number, it is possible for the next command to start pulling out some memory on its own because add had already moved on from that stage.
For branching command, the future commands are getting into the pipeline even before we know the conclusion whether to branch or not. If not branching it is great, since those commands can continue. But if branching however, we will have to flush out what's already coming to the pipeline!
And so is the purpose of branch prediction algorithm, instead of the default "not branching is better" sometimes it could think this branch will be taken, so the future commands will be those that follow the branch address rather than below the branch command like usual. Anyways, we could reduce all these trouble by avoiding the j commands. Not all conditionals results in branching commands.
The need for conditionals
if is often needed in optimized math library because it is still cheaper than otherwise having to do many math operations for real. Maybe take cheaper path if some value is under some threshold, because the error would become less noticable. So it is not purely evil, you have to justify the gain also.
In SLEEF library's paper (https://arxiv.org/pdf/2001.09258.pdf), it also analyze that other competing math libraries such as FDLIBM or Vector-libm have too many if in the code and not given enough priority, where SLEEF is actively trying to keep the conditional low.
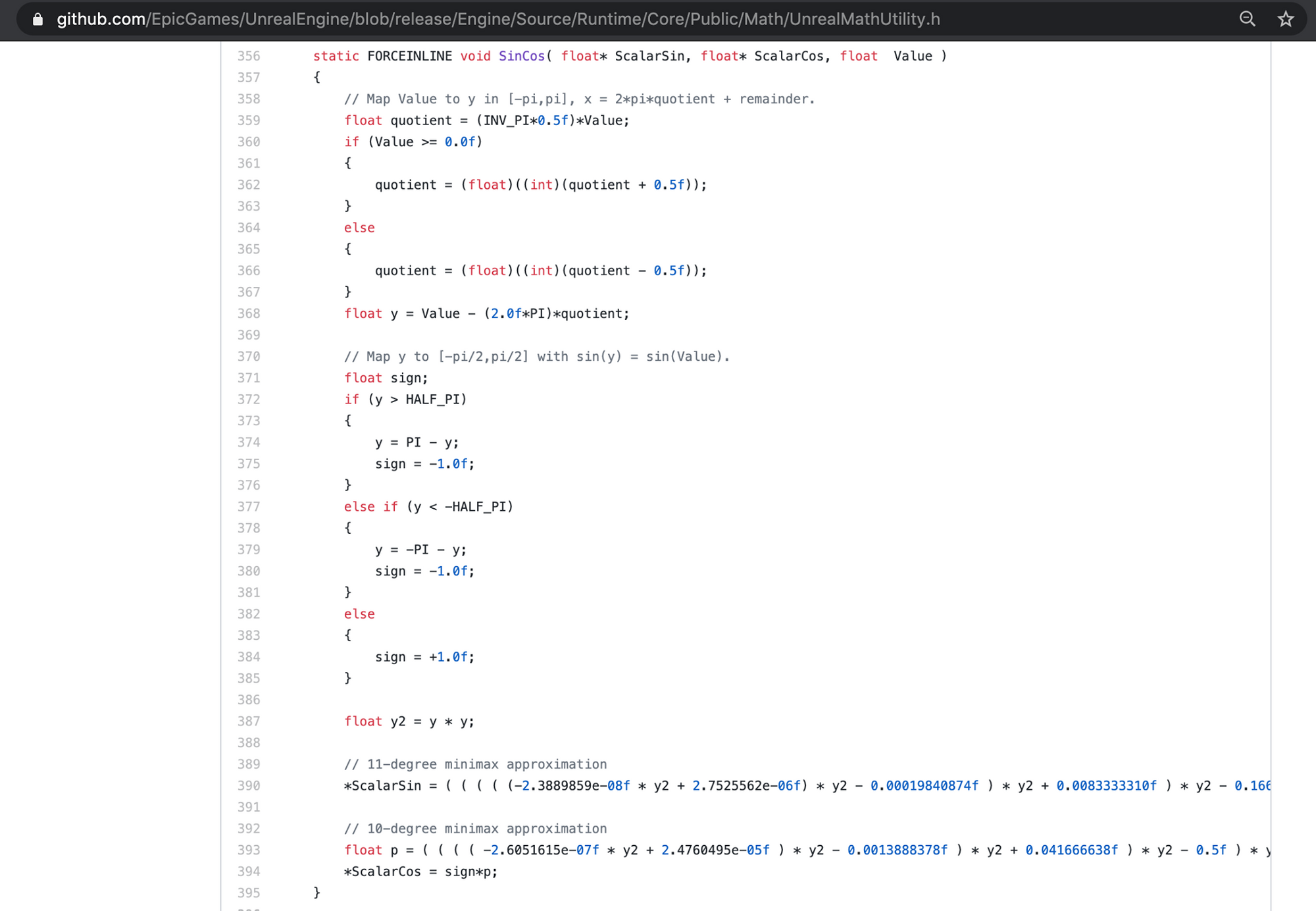
An another actual example from Unreal Engine's source code. In order to compute sincos it didn't really compute sin and cos, and not even sincos at the same time. Conditionals are used to determine the sign to be apply back at the end. Take advantage of symmetry of sin and cos, etc. So the computation could be generic enough. A lot of if else, but worth it even in hot code path if you really need a sincos.
Inline if / math.select
By using inline-if as much as possible, you are reducing the likelihood of this happening. However inline-if must result in a value. In some case it won't be possible.
In this picture the generated branching commands are highlighted. The final case do the same work, but got only 1 branching command. (math.select could be replaced by just ? : inline if syntax of C#, Burst know how to deal with them.)
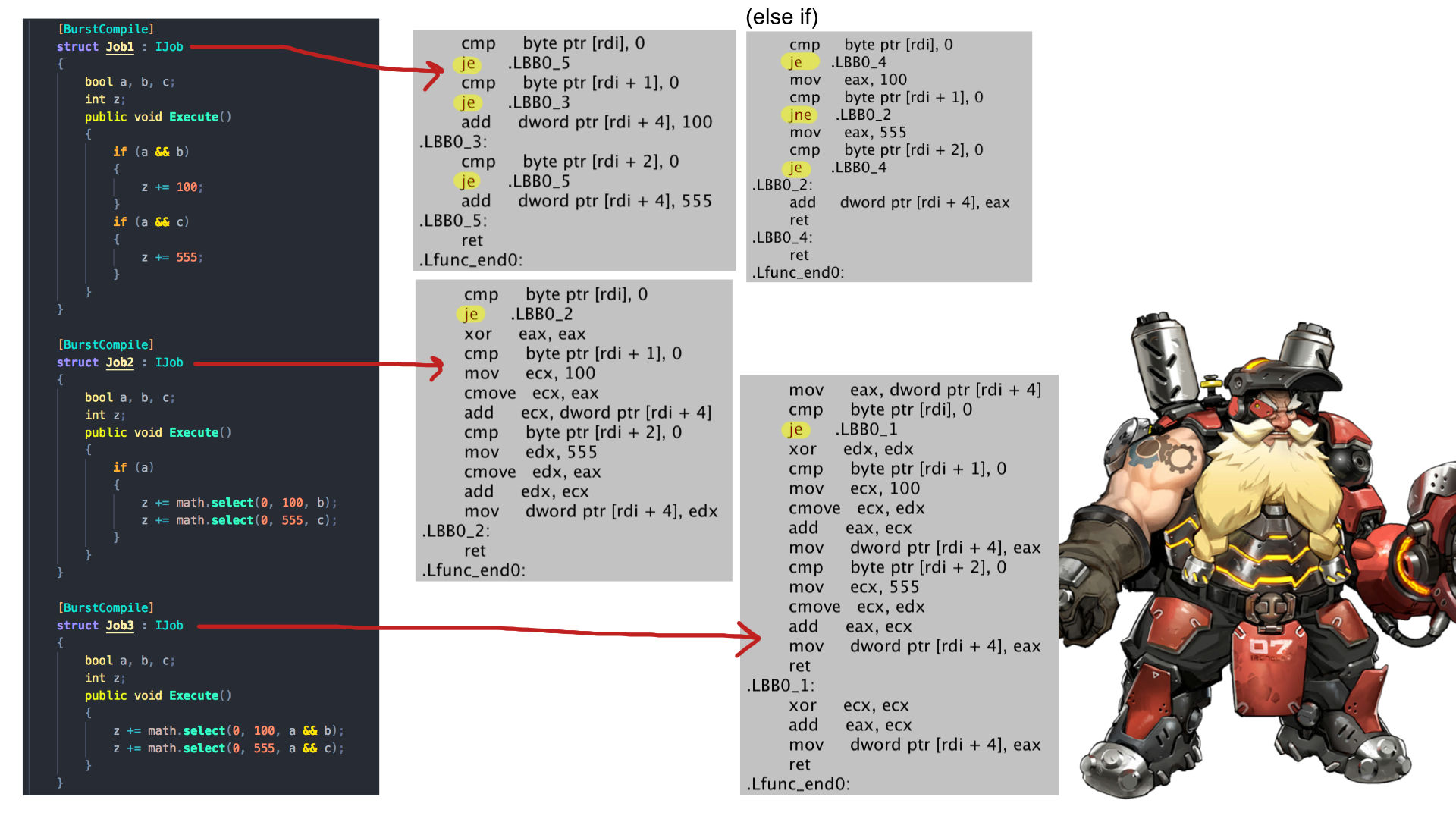
Our hero is the "conditional move" command cmove. It is able to test and assign at the same time if the test is a success. It doesn't count as branching command but got its own little "branch" in itself that will not trouble CPU that much about the prefetching.
Switch case
I found that using switch case with enum is extremely advantageous. Comparing the chain of if else, switch case with int, and switch case with enum, the final case produces just 1 branching assembly. The switch case got turned into something called "switch table" thanks to finite values of enum and thanks to this particular routine that just assign value. (It feels like an extension of inline-if, when you got more than 2 values to decide.)
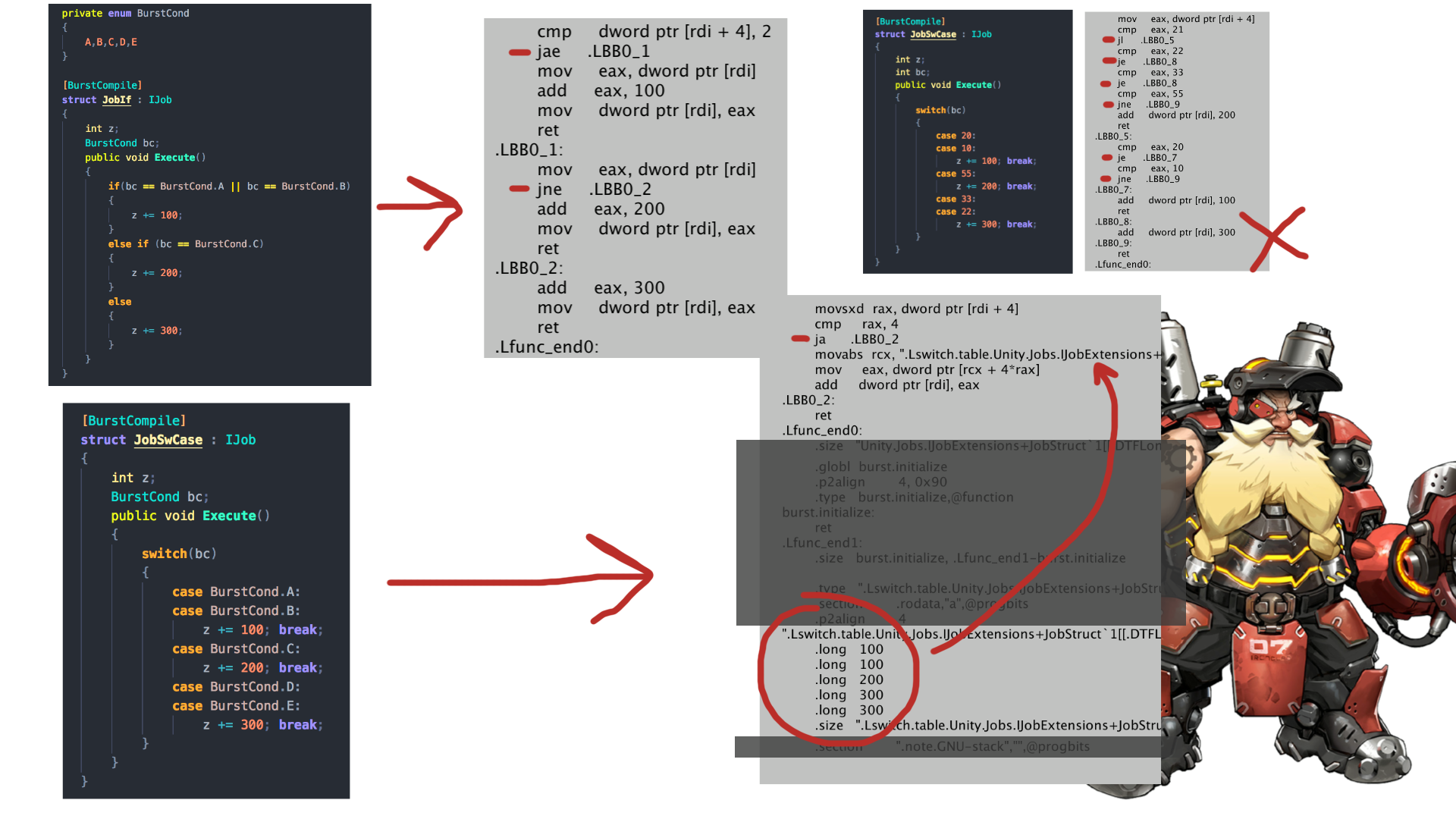
Smart inline-if
In some case Burst could convert bad if into inline-if if it is obvious to Burst that all it did is assigning value. These 2 jobs produces exactly the same assembly.
[BurstCompile]
public struct Compare1 : IJob
{
public NativeArray<int> question1;
public NativeArray<int> question2;
public NativeArray<int> answer;
public void Execute()
{
bool ans1 = question1[0] > question2[0];
bool ans2 = question1[0] == question2[0];
if (ans1 && ans2)
{
answer[0] = 555;
}
else
{
answer[0] = 666;
}
}
}
[BurstCompile]
public struct Compare2 : IJob
{
public NativeArray<int> question1;
public NativeArray<int> question2;
public NativeArray<int> answer;
public void Execute()
{
bool ans1 = question1[0] > question2[0];
bool ans2 = question1[0] == question2[0];
answer[0] = (ans1 && ans2) ? 555 : 666;
}
}
(But likely any more complex, you may start getting j commands. Please check manually.)
Bitwise operation vs boolean operation
Assembly tends to be very good with bitwise operation and got many specialized commands waiting for you. But not so good on branching. However, there is a fine line between bitwise operation and branching. In some case if you could replace a part of code that leads up to branching with bitwise operation, then you could be helping Burst.
This case, the generated assembly is the same.
[BurstCompile]
public struct And : IJob
{
public NativeArray<int> question1;
public NativeArray<int> question2;
public NativeArray<bool2> answer;
public void Execute()
{
bool ans1 = question1[0] > question2[0];
bool ans2 = question1[0] == question2[0];
answer[0] = new bool2(ans1 && ans2 , false);
}
}
[BurstCompile]
public struct Bitwise : IJob
{
public NativeArray<int> question1;
public NativeArray<int> question2;
public NativeArray<bool2> answer;
public void Execute()
{
bool ans1 = question1[0] > question2[0];
bool ans2 = question1[0] == question2[0];
answer[0] = new bool2(ans1 & ans2 , false);
}
}
But how about this?
[BurstCompile]
public struct And : IJob
{
public NativeArray<bool2> question1;
public NativeArray<bool2> question2;
public NativeArray<bool2> answer;
public void Execute()
{
for (int i = 0; i < answer.Length; i++)
{
answer[i] = new bool2(question1[i].x && question2[i].x, false);
}
}
}
[BurstCompile]
public struct Bitwise : IJob
{
public NativeArray<bool2> question1;
public NativeArray<bool2> question2;
public NativeArray<bool2> answer;
public void Execute()
{
for (int i = 0; i < answer.Length; i++)
{
answer[i] = new bool2(question1[i].x & question2[i].x, false);
}
}
}
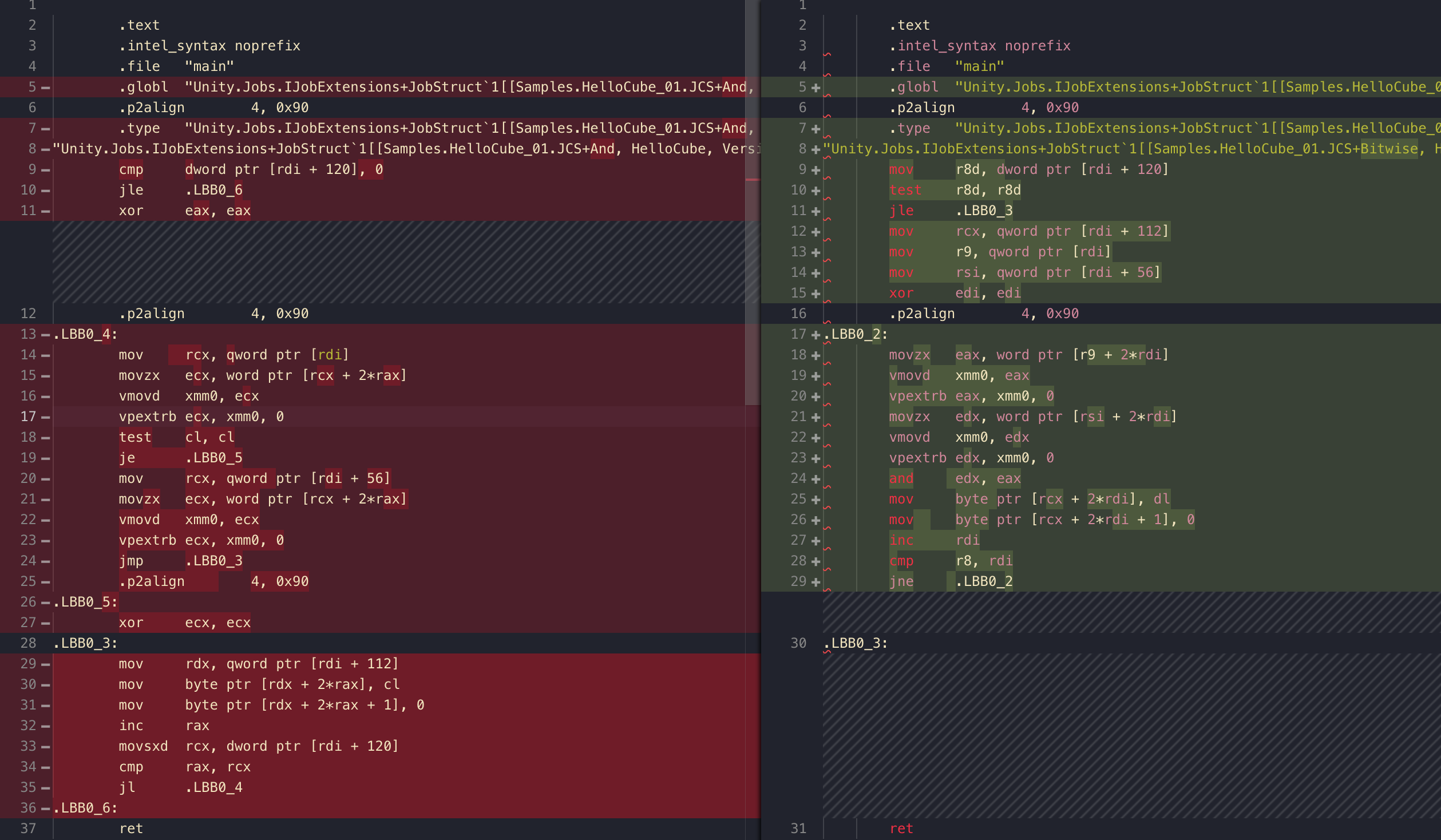
It is... quite different. vpextrb command on the left, extr stands for extract and b for byte integer. It is trying to get a boolean from bool2. And there you go! You see that je? je in the inner loop like this is definitely not cool. I am too lazy to translate all of this but the point is we got no branch in the inner loop for bitwise version.
It will be even cooler for bool4, of course.
[BurstCompile]
public struct And : IJob
{
public NativeArray<bool4> question1;
public NativeArray<bool4> question2;
public NativeArray<bool4> answer;
public void Execute()
{
for (int i = 0; i < answer.Length; i++)
{
answer[i] = new bool4(
question1[i].x && question2[i].x,
question1[i].y && question2[i].y,
question1[i].z && question2[i].z,
question1[i].w && question2[i].w
);
}
}
}
[BurstCompile]
public struct Bitwise : IJob
{
public NativeArray<bool4> question1;
public NativeArray<bool4> question2;
public NativeArray<bool4> answer;
public void Execute()
{
for (int i = 0; i < answer.Length; i++)
{
answer[i] = new bool4(
question1[i].x & question2[i].x,
question1[i].y & question2[i].y,
question1[i].z & question2[i].z,
question1[i].w & question2[i].w
);
//answer[i] = question1[i] & question2[i]; // <-- more stylish way of doing it, same assembly.
}
}
}
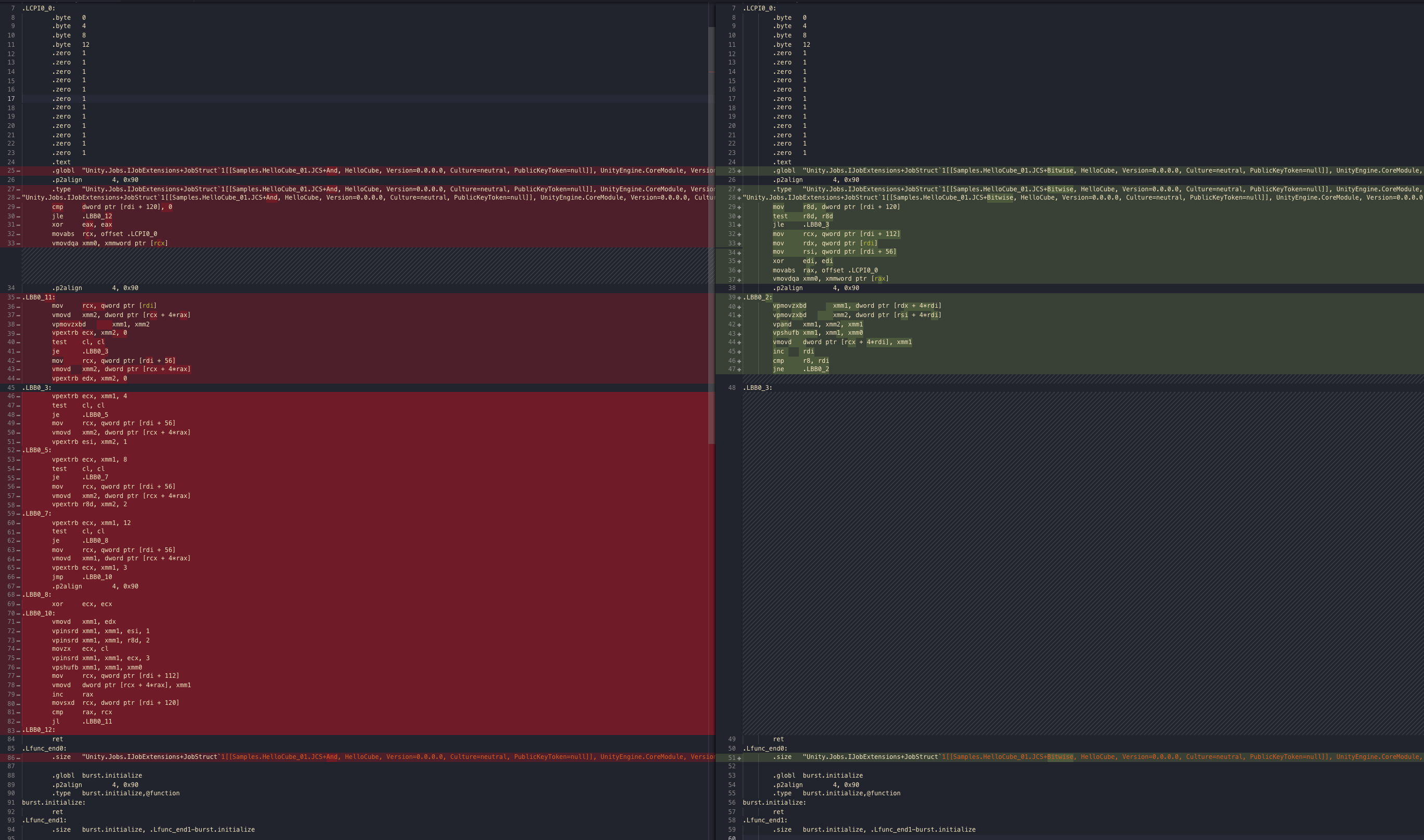
The left side turns into a monster full of je. On the right side we see multiple xmm. Again I am too lazy to translate anymore but the right side is probably a lot better... Also other type like float4 also got bitwise operator for use. If you got some special algorithm that could utilize them it could be very advantageous. tl;dr, try using & instead of && for example, where possible.
math.any / math.all
This could go in the Mathematics section but it is related to conditionals. In that section you learned that Burst will replace math._ with a set assembly better than what could be generated when you inline the method with its content.
any and all could "summarize" multiple booleans into one. It is essentially just a mass OR/AND where the things to OR/AND is each element of itself (Usable with all 2/3/4 variants). But this method has so many overloads that cover more than just bool234 variable! In which case it count the value 0 as false and other as true. Use it together wisely with bitwise operation I talked about from the previous section, you might be saving big performance!
Let's look at the generated assembly for inlining a chain of 3 || vs just using math.any to a bool4 so that it chain-OR with itself.
[BurstCompile]
public struct NormalOr : IJob
{
public NativeArray<bool4> a;
public NativeArray<int> result;
public void Execute()
{
for (int i = 0; i < a.Length; i++)
{
result[i] = (a[i].x || a[i].y || a[i].z || a[i].w) ? 444 : 555;
}
}
}
[BurstCompile]
public struct SimdOr : IJob
{
public NativeArray<bool4> a;
public NativeArray<int> result;
public void Execute()
{
for (int i = 0; i < a.Length; i++)
{
result[i] = math.any(a[i]) ? 444 : 555;
}
}
}
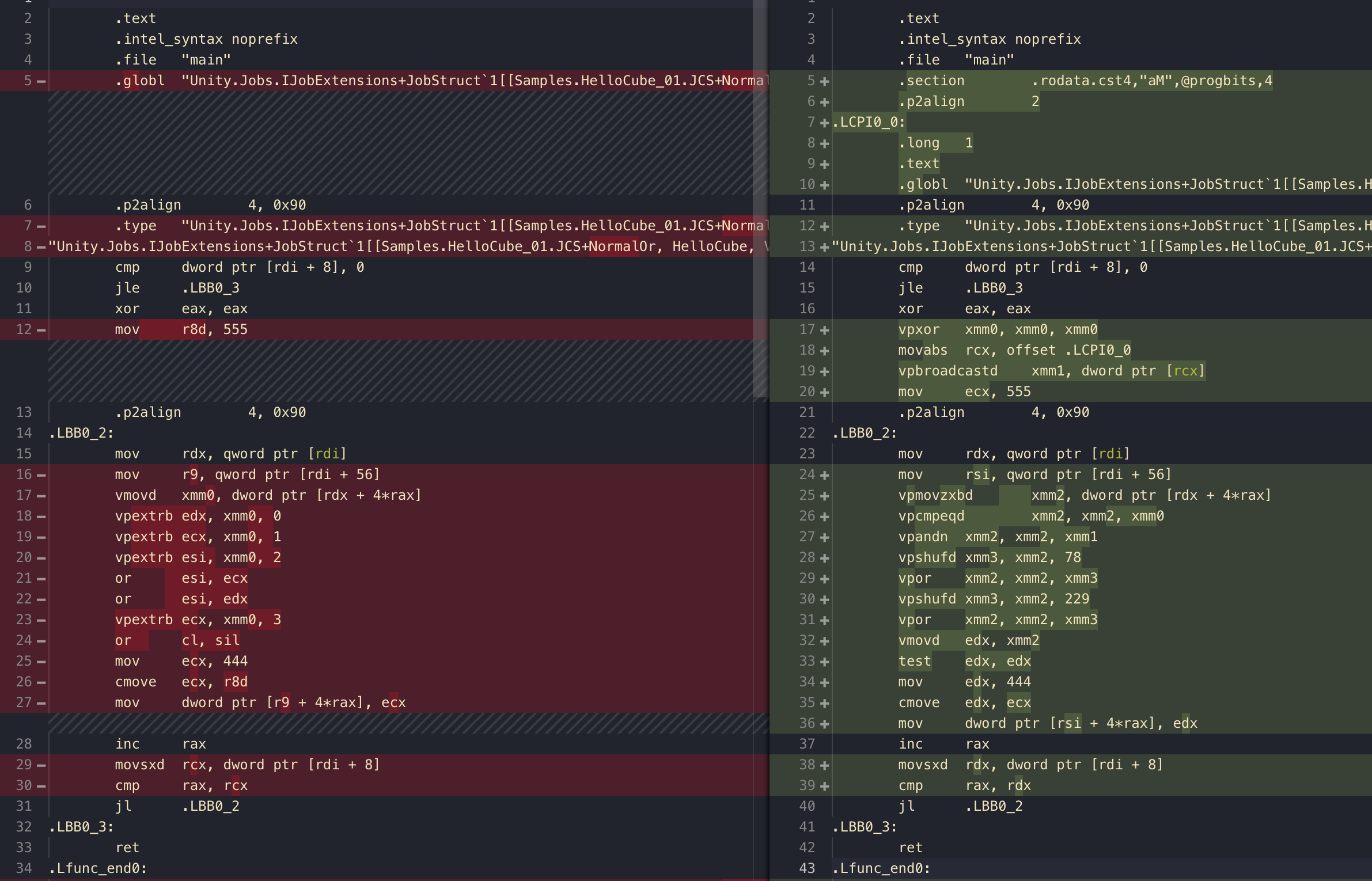
Start at the left side. This is very straightforward, vpextrb is the byte extraction command, as a bool is of size byte, and our bool4 has been moved to xmm variable for work, they are yanking each individual bool to 4 registers and just OR them up one by one. ( sil is the same as esi/rsi but taking only the lowest byte part, same with cl with ecx/rcx)
The right side is a bit difficult to understand. You have to notice that doing SIMD OR is easy! But the difficult part is SIMD commands tends to put each individual results in its own space. math.any/all wants a summary of each elements. This is in the same style as the dot product case you learned in Mathematics section where SIMD multiply was easy, but to sum each element up we have to do gymnastics. Maybe you could call it a SIMD-to-scalar pattern.
The hero of the "summary" part in this case is the vmovd command seen on line 32. When one side is a much bigger xmm register (128 bits/4 int/float or zero-padded bool) and the other side is a smaller 32 bit register ( edx is indicating the lower 32 bit of rdx), the command could extract only lower 32 bit part from the big xmm to move. Then our goal is to somehow make the final result of any/all arrives at lower 32 bit part of xmm ignoring other memory area, in order to finalize with this move command.
The SIMD OR/AND part is roughly as follows, but I think I don't understand it fully :
- Prepares all zeroes.
xorwith itself is a classic move to do all zero reset. - Prepares four ones lining up on 128 bit sized register. It looks like [0...0001][0...0001][0...0001][0...0001] if each bracket is 32 bit. Achieved by the broadcast command
vpbroadcastdwith a predefined constant 1, withdit knows each broadcast is of size double word = 32 bit. So we get 4 ones on 128 bit register. Keep this away for now. - Take out all 4
boolfrom memory to register to work on withvpmovzxbd. Because our work desk is a bigxmmbut we use it to work with a tiny byte sizedbool, the zero pad on the command is needed. The content ofxmmwould now looked sparse like this : [0...0000][0...0001][0...0001][0...0000] if the original content wasfalse true true false. - The next sequence of
vpcmpeqd(vector compare equal) thenvpandn(vector and-not) is what I am not quite sure of its intention. The compare is with all zeroes, resulting in essentially a negated/flipped bits. (Because when the right operand is locked at zero, 1 vs 0 = 0, 0 vs 0 = 1) However comparison puts ALL the bits in the double word as that. Continued from the last example, it is now like [1...1111][0...0000][0...0000][1...1111] (fill all bits with results which is a negation) vpandnwill then AND NOT with four ones. According to Intel manual it seems we NOT the left source then AND with the right source. The left source is the comparison result earlier. AND with right source which is four ones is just trying to filter out only the first bit from each double word. The result is now [0...0000][0...0001][0...0001][0...0000] it is exactly the same as before!! So I guess all this is to "clean up" the bad memory that might get in the calculation??

- The next shuf-OR-shuf-OR sequence is (finally) the real work.
vpshufd(becamepermilin the case of using floating point I believe) is able to rearrange its own elements in any order we wish. The shuffle gymnastic's intention is to line up so that the shuffled could do SIMD operation to itself that was unshuffled. Look at the image for overview. Red arrow means you should pay attention, yellow arrows means you can ignore that shuffle. Replace the blue OR with AND formath.all. - The number 78 is saying that order, break down into 4 pairs of 2 bits number 78 = 01 00 11 10 (1 0 3 2) This setup is get #3 and #2 elements to align with its former self #1 and #0 elements, and have them do SIMD OR/AND (depending on
anyorall). I think you don't have to care about why element 1 0 has to move there, so in the picture I note that with yellow arrows. - The next shuffle 229 = 11 10 01 01 (3 2 1 1) almost means all elements goes straight down without any shuffle, except that element 1 is put in the element 0 slot instead. And that's what you have to care because it is a setup to get element 0 and 1 to fight with each other again by lining up element 1 with previous 0. Then we do SIMD OR/AND again. But you can pay attention to only the first element.
- The grand final result is already together in the lowest 32 bit area of
xmmas I said in the beginning, and thereforevmovdput the product in place. Before you know it have already got your triple OR with it's own elements, with just 2 SIMD OR operations!
UPDATE : It was updated to be better on November 2019. The analysis result above was from about one year earlier.
Automatic vectorization in action
The first one just increment all elements of itself. The 2nd one increment but store in an another storage. Who would win?
[BurstCompile]
public struct Vectorize1 : IJob
{
public NativeArray<int> ints;
public void Execute()
{
for (int i = 0; i < ints.Length; i++)
{
ints[i] += 555;
}
}
}
[BurstCompile]
public struct Vectorize2 : IJob
{
public NativeArray<int> ints;
public NativeArray<int> intsDestination;
public void Execute()
{
for (int i = 0; i < ints.Length; i++)
{
intsDestination[i] = ints[i] + 555;
}
}
}
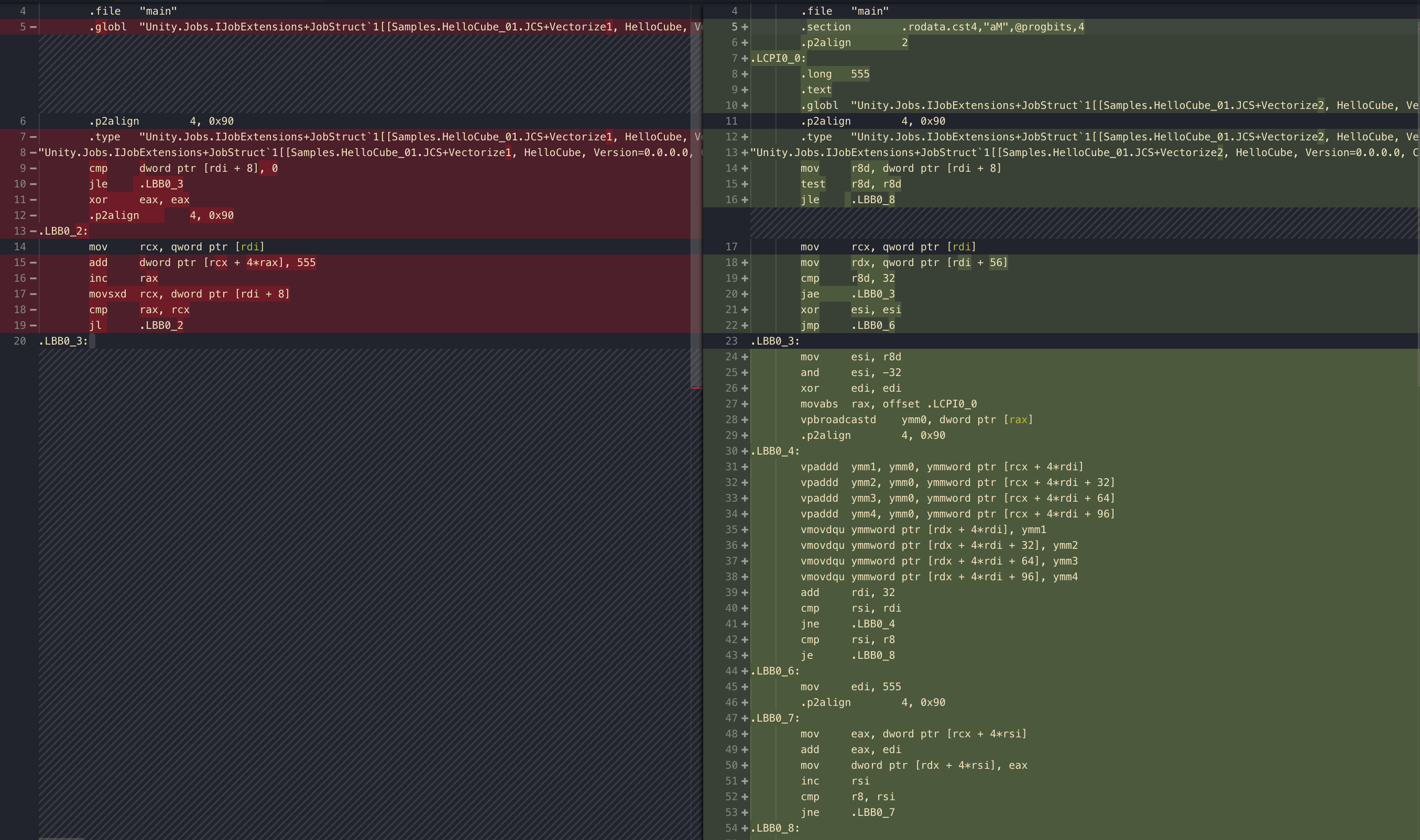
While the left side is straightforward, the right side looks unexpectedly complicated!
What you see in the right side is the power of no alias analysis that enabled vectorization. By ensuring that the memory area is not connected to the same place around here, we have more chance of using SIMD assembly even if the data type is just an int one after another. For float4 you understand that it is 128 bit and goes well with xmm register size . But why could int? Here's all of the code.
.LCPI0_0:
.long 555
...(skipped)...
mov r8d, dword ptr [rdi + 8]
test r8d, r8d
jle .LBB0_8
mov rcx, qword ptr [rdi]
mov rdx, qword ptr [rdi + 56]
cmp r8d, 32
jae .LBB0_3
xor esi, esi
jmp .LBB0_6
.LBB0_3:
mov esi, r8d
and esi, -32
xor edi, edi
movabs rax, offset .LCPI0_0
vpbroadcastd ymm0, dword ptr [rax]
.p2align 4, 0x90
.LBB0_4:
vpaddd ymm1, ymm0, ymmword ptr [rcx + 4*rdi]
vpaddd ymm2, ymm0, ymmword ptr [rcx + 4*rdi + 32]
vpaddd ymm3, ymm0, ymmword ptr [rcx + 4*rdi + 64]
vpaddd ymm4, ymm0, ymmword ptr [rcx + 4*rdi + 96]
vmovdqu ymmword ptr [rdx + 4*rdi], ymm1
vmovdqu ymmword ptr [rdx + 4*rdi + 32], ymm2
vmovdqu ymmword ptr [rdx + 4*rdi + 64], ymm3
vmovdqu ymmword ptr [rdx + 4*rdi + 96], ymm4
add rdi, 32
cmp rsi, rdi
jne .LBB0_4
cmp rsi, r8
je .LBB0_8
.LBB0_6:
mov edi, 555
.p2align 4, 0x90
.LBB0_7:
mov eax, dword ptr [rcx + 4*rsi]
add eax, edi
mov dword ptr [rdx + 4*rsi], eax
inc rsi
cmp r8, rsi
jne .LBB0_7
.LBB0_8:
vzeroupper
ret
Here's the first section.
mov r8d, dword ptr [rdi + 8]
test r8d, r8d
jle .LBB0_8
mov rcx, qword ptr [rdi]
mov rdx, qword ptr [rdi + 56]
cmp r8d, 32
jae .LBB0_3
xor esi, esi
jmp .LBB0_6
mov and rdi is the register for "data", in this case the job struct's public field. And so rdi + 8 is probably getting the Length inside NativeArray. test is just and with itself and it would be false only if it is 0. That is if the length is 0 we skip all the work.
When we got past that jle the mov mov is probably preparing the two NativeArray for iteration. Then we see cmp the length again with 32. If it is go to .LBB0_3 "the batched routine", or else go .LBB0_6 "the one-by-one routine". That is, vectorization works only if your length is 32 or higher. However it doesn't really processes 32 int all in parallel at once, but rather divided into multiple sets of ymm operations.
vpbroadcastd ymm0, dword ptr [rax]
.p2align 4, 0x90
.LBB0_4:
vpaddd ymm1, ymm0, ymmword ptr [rcx + 4*rdi]
vpaddd ymm2, ymm0, ymmword ptr [rcx + 4*rdi + 32]
vpaddd ymm3, ymm0, ymmword ptr [rcx + 4*rdi + 64]
vpaddd ymm4, ymm0, ymmword ptr [rcx + 4*rdi + 96]
vmovdqu ymmword ptr [rdx + 4*rdi], ymm1
vmovdqu ymmword ptr [rdx + 4*rdi + 32], ymm2
vmovdqu ymmword ptr [rdx + 4*rdi + 64], ymm3
vmovdqu ymmword ptr [rdx + 4*rdi + 96], ymm4
Next up is the batched routine since you see tons of ymm. What to add is the constant 555 which will be "VEX packed broadcast to double word" ( vpbroadcastd , this command only has the v version) to ymm0. This command is from AVX extension and is quite special.
It repeat the value all over the memory area, setting up a potential combo with SIMD instructions to come. Because ymm0 is a 256 bit register and could contain 8x 32 bit integer, and you say "double word" which essentially means int in C#, you could think the ymm0 now looks like this : 555 555 555 555 555 555 555 555 at the moment.
You then see 4 vpaddd. Because the length of your array must be over 32 to come here you can guess each one do things to 8 int. vpaddd is read as "VEX packed add to double word". Depending on what size of register you give this command you get that many packed. In this case ymm0 is a 256 bit sized register. vpaddd make use of all of all broadcasted 555 to do SIMD to the pointer on the right operand. With p we see that the add should be packed. I don't know if packed in this case improve performance or not since we are already in integer domain. (Packed helps compute the floating point)
What is vmovdqu ? vmov is VEX supported move. u is unaligned. dq should indicates double quadword. Quadword is 64 bit. Double quadword is then 128 bit. In this case we are using it with ymm register which is of size 256, I guess it do that 2 times. (If xmm, then it is sized as 128 bit. This command is still usable.) So basically vpaddd to a temporary memory area, and then a complementary xmm to put that into place. You don't see p in the mov command here, but since they operate in integer domain I think this is the fastest it could. (For floating point it would be something like movaps where it could be packed.)
.LBB0_6:
mov edi, 555
.p2align 4, 0x90
.LBB0_7:
mov eax, dword ptr [rcx + 4*rsi]
add eax, edi
mov dword ptr [rdx + 4*rsi], eax
inc rsi
cmp r8, rsi
jne .LBB0_7
Finally, because the one-by-one routine sits directly under the 32 int routine, the left over loop cound will continue here in a normal fashion one by one. When your count is lower than 32, it jumps to here immediately and you don't get those nice ymm usage.
Investigating the lowest count to vectorize
You learned that Unity not only try to use the largest ymm register, but do so several times in a row (In this case 4 times) likely as a balance to lessen the amount of for loop requirement check (Because each loop check will involve j command! You already learned how it could cost performance). Therefore there is a minimum count of data for your routine to get into a vectorization routine. Probably depends on your data type too, so why not try out the other data type?
[BurstCompile]
public struct VectorizeVarious : IJob
{
public NativeArray<byte/short/int/long/float/double> ints;
public NativeArray<byte/short/int/long/float/double> intsDestination;
public void Execute()
{
for (int i = 0; i < ints.Length; i++)
{
intsDestination[i] = (byte/short/int/long/float/double)(ints[i] + 555);
}
}
}
I am too lazy to paste the assembly for each one, but here's the summary
byte: The 4xvpaddd+vmovdqustill remains. But the minimum count required is now 128 instead of 32.short:vpaddd+vmovdqureduced to just 2x from 4x, and minimum count remains the same at 32.long: The 4xvpaddd+vmovdqustill remains. But the minimum count required is now 16 instead of 32.float: It is exactly the same asint, exceptvmovdquis nowvmovups. (Packed help floating point calculation, probably.)double: The same asfloatbut minimum count is now 16 instead of 32.
Well, it is just for educational purpose. In real use maybe you have already got more than these minimum count and be happy that Burst is doing good work for you.
From the talk
The same explanation was in the Unite LA talk from 2018.

What's wrong with the first (left) job?
You think there is no reason that the first one could not be vectorized. I think so too, so I tried changing that up a bit :
[BurstCompile]
public struct Vectorize1 : IJob
{
public NativeArray<int> ints;
public void Execute()
{
for (int i = 0; i < ints.Length; i++)
{
ints[i] += 555;
}
}
}
[BurstCompile]
public struct Vectorize1Fixed : IJob
{
public NativeArray<int> ints;
public void Execute()
{
for (int i = 0; i < ints.Length; i++)
{
var foo = ints[i];
foo += 555;
ints[i] = foo;
}
}
}
Turns out just change += in place to addition then put it back, Burst could understand it and produce vectorized assembly equivalent to the 2 NativeArray job! And that's why folks, you have to use the Burst debugger in your hot code and "poke" Burst around if it is not doing what you want. (And so also that's why it is important to understand the assembly to know what's wrong and what you are expecting to get) Also I have already reported this to Unity just in case it is a bug.
Edit : This is fixed in Burst 1.0.0 preview 9. But anyways the takeaway is that knowing what's going on is beneficial.
Vectorization vs. the actual vector / matrix
What if we use int4x4 or int4x2 instead of just an array of int and leave it for Burst to vectorize it?
[BurstCompile]
public struct VectorizedLinear : IJob
{
public NativeArray<int> source;
public NativeArray<int> destination;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
var foo = source[i];
foo = foo * 555;
destination[i] = foo;
}
}
}
[BurstCompile]
public struct NotMatrix : IJob
{
public NativeArray<int4> source;
public NativeArray<int4> destination;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
var foo = source[i];
foo = foo * 555;
destination[i] = foo;
}
}
}
[BurstCompile]
public struct PerfectSize : IJob
{
public NativeArray<int4x4> source;
public NativeArray<int4x4> destination;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
var foo = source[i];
foo = foo * 555;
destination[i] = foo;
}
}
}
[BurstCompile]
public struct WeirdSize : IJob
{
public NativeArray<int2x3> source;
public NativeArray<int2x3> destination;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
var foo = source[i];
foo = foo * 555;
destination[i] = foo;
}
}
}
[BurstCompile]
public struct OkSize : IJob
{
public NativeArray<int2x4> source;
public NativeArray<int2x4> destination;
public void Execute()
{
for (int i = 0; i < source.Length; i++)
{
var foo = source[i];
foo = foo * 555;
destination[i] = foo;
}
}
}
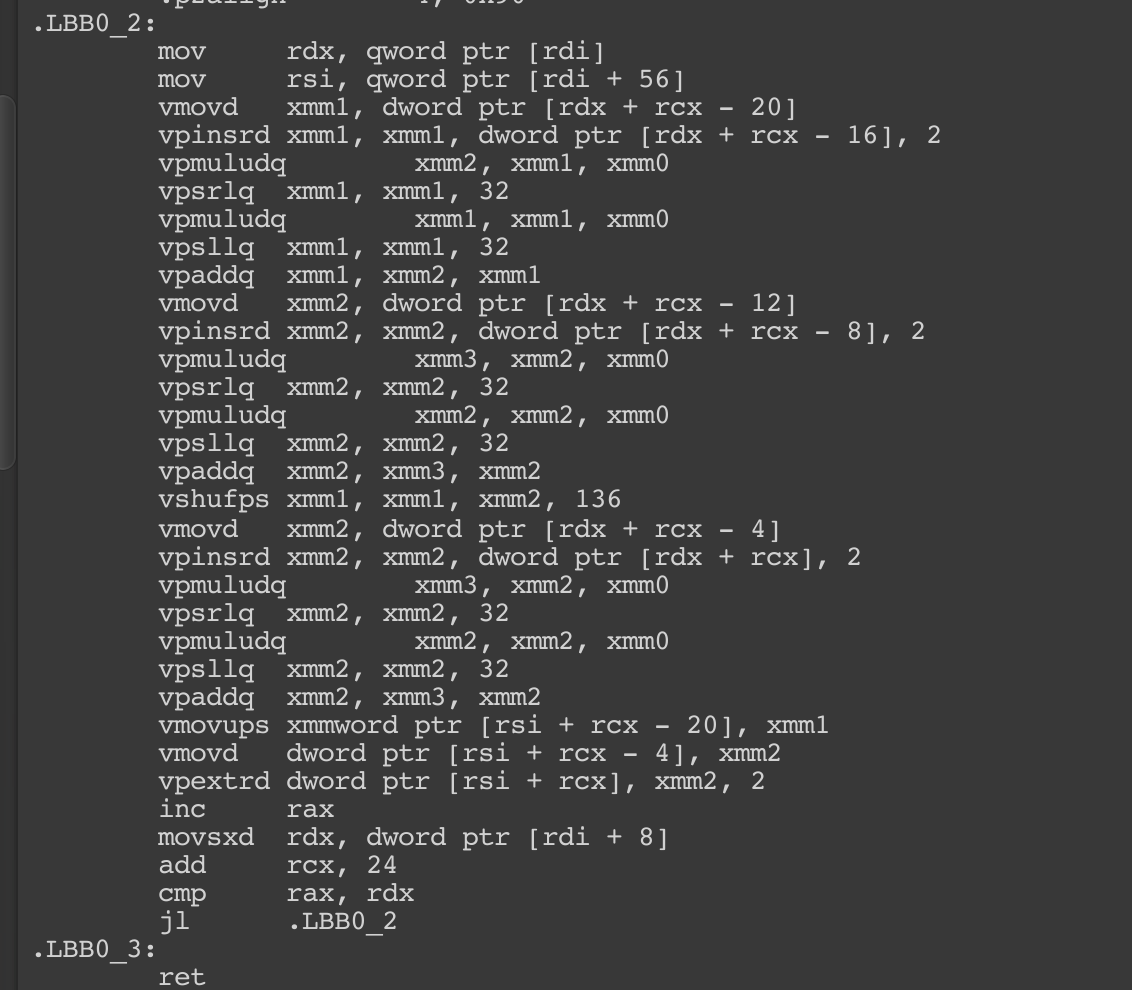
VectorizedLinear: The same as before, the required count to enter vectorizedymmroutine is 32, otherwise linearly iterate.NotMatrix:int4is exactly the size ofxmm, so that is used without any auto vectorization.PerfectSize: Thisint4x4precisely use 4xmmregister to complete the task, it is not like assembly will have a magic register that holds the entire matrix. So the performance is similar toint4, but you doforloop branching less by 4 times.WeirdSize: Multiplying a number intoint2x3results in this. At least you seexmmbeing utilized.
OkSize: Thisint2x4looks to be a nice number, but still it requires too much gymnastic to operate and have it land in the same shaped container.
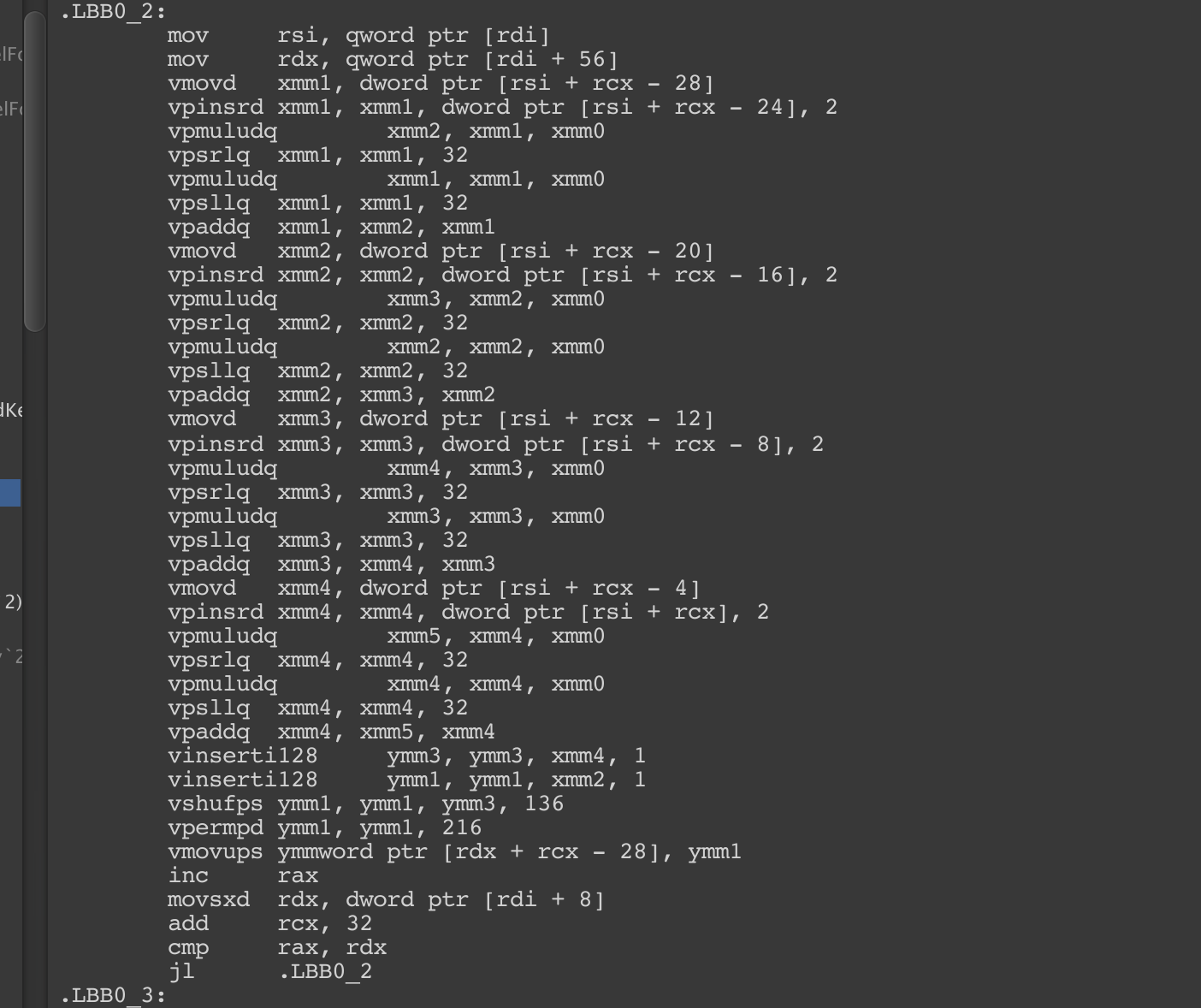
So.. if for any reason you are trying to change your int array to packed matrix thinking that matrix could do better, you probably better left it linear and leave it to Burst to vectorize. (Given that you have high enough count, or otherwise in some specific case int4 or int4x4 could have an edge...)
Other matrix operation though, might be fast to perform (mostly related to computer graphics) so you should try for yourself.
For loops : < vs !=
Did you forget there is a conditional in your for loop? Because that will add j assembly for you on every loop I would like to examine this case. Usually the for loop is intended to go up by 1 on each step (and it is the basic "vectorizable" case). So in this case, < and != achieve the same thing.
[BurstCompile]
public struct ForLE : IJob
{
public NativeArray<int> a;
public NativeArray<int> b;
public void Execute()
{
for (int i = 0; i < a.Length; i ++) //LESS THAN
{
b[i] = a[i] + 555;
}
}
}
[BurstCompile]
public struct ForNE :IJob
{
public NativeArray<int> a;
public NativeArray<int> b;
public void Execute()
{
for (int i = 0; i != a.Length; i ++) //NOT EQUAL
{
b[i] = a[i] + 555;
}
}
}
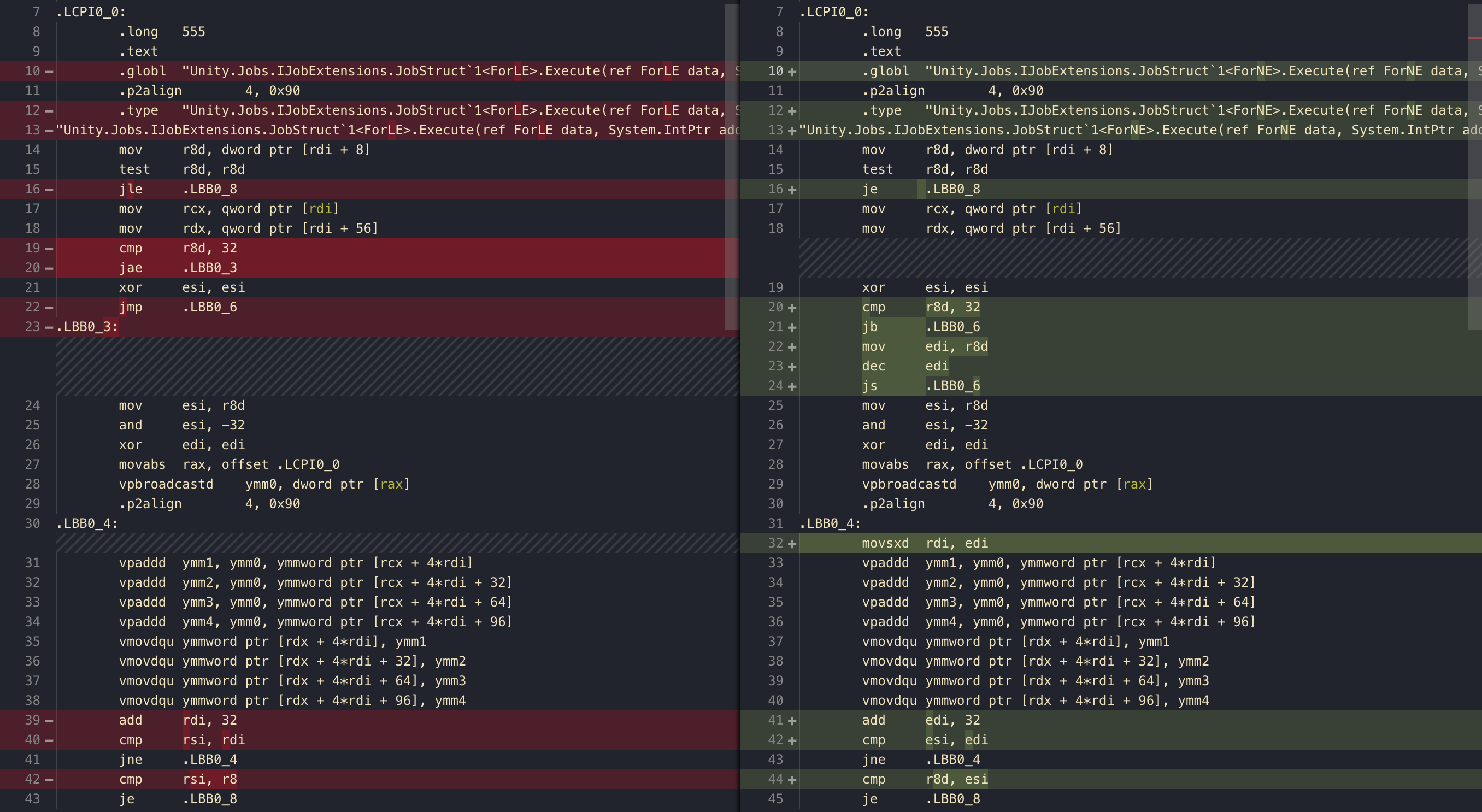
The assembly here is different for what could do the same thing. Which one is better?
testthenjlevsje. This is just to handle length 0 and thetestis just asking if it is 0. All jump commands just ask status flag, so should be the same performance?- Bottom most is the check case after each vectorized run. It is the same. Meaning that the only difference is the condition to enter the first vectorized run.
jbon the right side stands for jump if below 32, anddec+jsjump if signed combo is an attempt to zero check in a stylish way? (So 0 decremented by one would result in signed number)- So I would like to conclude the difference is not significant since it is not in a hot loop path. (Where vectorized loop actually happens)
Ok, but what about non vectorizable job where all for conditional became "hot" times your Length that you are working on? In this test I intentionally change the simple copy job to accumulation job, an incarnation of evil that easily prevents any automatic vectorization since it needs to wait for the previous loop.
[BurstCompile]
public struct ForLE : IJob
{
public NativeArray<int> a;
public NativeArray<int> b;
public void Execute()
{
for (int i = 0; i < a.Length; i++)
{
b[0] += a[i] + 555;
}
}
}
[BurstCompile]
public struct ForNE : IJob
{
public NativeArray<int> a;
public NativeArray<int> b;
public void Execute()
{
for (int i = 0; i != a.Length; i++)
{
b[0] += a[i] + 555;
}
}
}
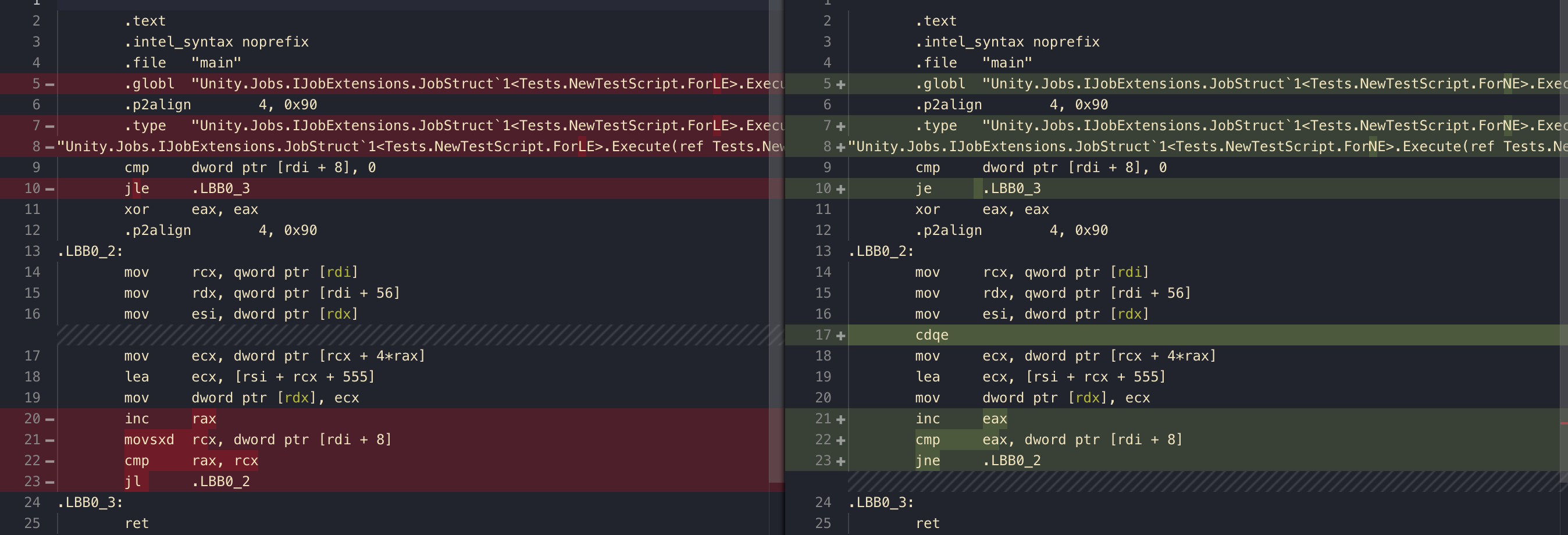
- We are with an extra move command
movsxdon the left side! - On the right side with
cdqe, "convert double word to quad word". This has no operand, it seems to work onaxregister exclusively from Intel's manual. (In this architecture,eax) jlvsjneis checking the status flag produced fromcmp, it should have the same performance.- Now it looks like
!=could have an edge over<because we saved one move command.
Why? How cmp really works is just a subtraction and see the result. The != case we are able to cmp with the memory on the end of each loop. For <, we compare register vs register and that needed a move to get the content out.
For < we do movsxd first. This sx is a sign extension. In order to produce the correct result for jl test, the cmp subtraction need to produce the correct answer first.
On a contrary with jle test we just care that the subtraction cmp results in 0 or not. It doesn't matter if the subtraction produces flipped sign or something because that's still not 0. (I guess)
Is it worth the trouble to change all < to != then? Let's benchmark how faster != could get over <. The things to be accumulate was randomized with Unity.Mathematics.Random. Each Bursted accumulation test is repeated 1000 times (except 1 million elements test where it is repeated only ~400 times) and average the result on Xiaomi Mi A2 Android phone.
| Elements | < (avg. ticks) | != (avg. ticks) |
|---|---|---|
| 100 | 370.17 | 336.84 |
| 1000 | 1335.61 | 1329.53 |
| 10000 | 11146.19 | 11294.92 |
| 100000 | 109300.63 | 110425.04 |
| 1000000 | 1086462.09 | 1095331.44 |
Well, I see no meaningful difference. So in short just use < like you used to in all cases, vectorized or not. (I wasted time for nothing!! At least now you don't have to.)
Nested for loop iteration
Burst could mostly understand your for(int i = .. loop when you just use that i for some native containers. What if we have 2 for loops and use both i and j to get/set value?
[BurstCompile]
private struct Vectorized : IJob
{
public int jobCount;
public NativeArray<int> sumOccurrence;
[DeallocateOnJobCompletion] [ReadOnly] public NativeArray<int> occurrence;
public void Execute()
{
for (int j = 0; j < jobCount; j++)
{
for (int i = 0; i < 256; i++)
{
var sum = sumOccurrence[i];
sum += occurrence[(j * 256) + i];
sumOccurrence[i] = sum;
}
}
}
}
[BurstCompile]
private struct NotVectorized : IJob
{
public int jobCount;
public NativeArray<int> sumOccurrence;
[DeallocateOnJobCompletion] [ReadOnly] public NativeArray<int> occurrence;
public void Execute()
{
for (int i = 0; i < 256; i++)
{
var sum = sumOccurrence[i];
for (int j = 0; j < jobCount; j++)
{
//var sum = sumOccurrence[i];
sum += occurrence[(j * 256) + i];
//sumOccurrence[i] = sum;
}
sumOccurrence[i] = sum;
}
}
}
This is a job to sum up values in a much longer array of size 256 * jobCount to a smaller array of size 256. The key highlight is the (j * 256) + i indexer that uses 2 iterator. Both job could do the same work. And we learned about iteration and cache hit, the first job's design would be friendlier to the cache since inner loop is i and it is not being multiplied, so it goes forward smoothly.
I want to say that not only the 2nd job is a bad design for cache, also Burst couldn't vectorize it! (By the way if you replace jobCount with a constant value, Burst could manage to vectorize the routine. But the design isn't great anyways.) You notice the commented line, I could move the the fetch/assign out from inner loop but it didn't make a difference in the generated assembly.
Mathematics savvy reader may notice I could replace (j * byteSize) + i with math.mad(j, byteSize, i), but in this case it produces the same assembly as the multiply-and-add was already became vectorized routine (and so became linearly parallel, no multiply anymore).
Lesson learned
- There are cases where things could not be vectorized. Understanding what assemblies are available for use help you "draft" in your mind what C# code would be great for Burst to transform. (While not actually have to write any assembly)
- There is a minimum count for each vectorized routine.
- Sometimes Burst fails to optimize the code. Just changing the shape of code around could help correct Burst. I mean, ideally it should be able to optimize all code when it is mature enough, but never hurt to be able to expect and spot mistakes in the generated assembly.
Whew! Isn't it warms your heart that you can see and control the output assemblies from your precious code? In a way I am more happy of this than Unity being 100% open source because you know, these are my code...
Interesting external links
There is a port of popular benchmark programs to C# and let Burst compile that back, to compare with other solutions that compile those programs in their native C++ form. It's very interesting, and Burst is competitive!
https://github.com/nxrighthere/BurstBenchmarks
Be sure to follow the link to the forum and read comments from Unity team as well.