The Chunk data structure
Chunk is a unit of data storage of ECS that is central to performance gained. In usual OOP, you simply has address of variables and you simply go to that, but the point of OOP is to obfuscate that away and let you think in objects that you can relate to it more as a human in real world.


Chunk is a unit of data storage of ECS that is central to performance gained. In usual OOP, you simply has address of variables and you simply go to that, but the point of OOP is to obfuscate that away and let you think in objects that you can relate to it more as a human in real world.
It may appears at first that chunk is an internal efficient backend of Entities package in a sense that the package "powered by". But you should change your thinking, you have to pay attention on every commands how would your data ended up in how many chunks. This is data-oriented design, please take that literally!
Powered by chunks

The concept is quite simple, we just have a bigger container... but it may not be a "just". In fact this is central to million of functions in the package.
Let's imagine you have a pile of toys. If you get 4 cardboard boxes with label "clay", "bad clay" (color mixed up like mud/shit), "lego", "bad lego" (no longer fits with the good one), when you finished categorize them up (and also ensure any new lego or clay go into the correct box) then you can imagine when you want to play just a lego you could easily skip the "clay", "bad clay", and "bad lego" boxes. You want to throw away some toys? Throw that 2 boxes "bad clay" and "bad lego" away is logical.
Unity ECS package is doing that. The Entity Component System could be simplified to just this : "An optimized C# database where any new data are automatically categorized, any old data always adapted to sit well with new data, and a bunch of API to do things really fast with them while let them stay in that optimized shape."
Out of analogy and to an actual benefirs. With a bigger chunk unit that knows its own contents to some extent, it is possible to :
Perform rough and fast query
We are not talking about SQL style WHERE here which sounds like you would need an iteration through all the things. Only things that are common in attributes could be in the same chunk, you can imagine just check the chunk and not its content, saving time.
You must exploit this behaviour. The tag component and shared component data are something that you could use to "just chunk them up". There is nothing wrong with not using the data aspect of them. This is data-oriented, any operation that manipulates data to the shape that is advantageous is a win.
Batched operation
Some operation could just iterate through interested chunks instead of how many contents inside it and do things. The chunk may need to reform itself in some unfortunate cases, but it is better anyways that the outer loop could run through chunks instead of through little data. Check out what the entity manager could do per chunk instead of per entity.
Fixed size chunk allows risky, no check operation
Memory operation would usually cost more than mathematical operation. But when they are needed, nothing beats a dumb copy or delete where you just say from this memory to that memory address. Therefore larger the memory area you could do this without care about its content the faster the opertion. Becauses chunks are currently at fixes 16kB size, risky memory operation is possible that the end product is immediately usable.
Imagine the previous analogy, you wanna throw away "bad clay" and "bad lego" boxes. You may iterate through all boxes, look at each one, and pick up the bad ones one by one and throw each away. But what if you (you are the Entity Manager) know all the "bad X" boxes are always next to each other and you kept count how many bad boxes you got? Instead of throwing 16kB box then an another 16kB box, you can use mathematics and throw away 16kB * 2 amount of data as soon as you are at the first one. The actual optimization maybe different than this, but it is to illustrate that fixed chunk size is not a limitation. It actually helps speed things up thanks to multiplication math.
Mark on the chunks
Cool things you could do when you got chunk is on the chunk's header. Imagine the previous analogy, you can put an another sticker label on your "lego" box that says what was the previous latest day you bought new one and add to the box and write with an erasable ink. For fun, or to see if you finally grow out of playing legos when you haven't bought any for a long time by comparing with the current date. This is the version number mechanism in ECS that allows even more work skipping and filtering.
There maybe more fun things to add to the chunk header in the future as long as it applies to all its data. You know when was the last day you bought any new lego, but you don't know which exact lego was the last one (this is the compromise of doing things in box/chunk), but that's fine! Because you just want to know the date, or otherwise you will have to paste the label on the lego piece which ruins it. The same reason, ECS package works on chunk unit not without compromise about accuracy, but that allows efficiency first and foremost.
Clear boundary for parallel operation
We are still with lego boxes.. imagine now you want just the green lego, no matter it is bad or good to mold into a mush of green goo. Green clay doesn't work, luckily you see 2 boxes of "clay" and "bad clay" and filter them out immediately. You didn't separate lego by color before, and therefore you must search through all pieces in the "lego" box and "bad lego" box.
However you have got your mom! You call in your mom and hand her an entire "bad lego" box and ask her to separate the green pieces out for you. Then you also do the good "lego" box at the same time. There you go, parallelism. Your mom can take the box to kitchen and do it while you stay in your room. If the lego was just one box of mixed good and bad, you and your mom working on the same box may pose a risk of picking the same piece or hand getting in the way of each other. What if you instead got 2 boxes of "bad lego"? Not intentionally though because just one was too much to fit in one 16kB box, but it turns into an advantage now because you can additionally call your dad to help with that additional box.
Your mom and dad are worker threads. There are things that threads shouldn't do at the same time to the same thing. Chunk gives you a clear unit of parallel operation that make it easy to just say, this thread do this chunk, this thread do that chunk, without expensive check whether an operation will clash or not. ECS package will do this almost automatically, provided that you play in its rule.
*Maybe an even better approach : You got many more boxes that categorize legos in colors. And you now don't even need your mom to separate green ones, or still get your mom/dad to parallel find the only pieces with more than 8 studs among the green good/bad boxes because it would make an even better green goo. This is the shared component data filtering, with that shared data is the color of lego. Color.Green is shared among all pieces in the green box by not actually assigned to any piece in the box, instead Color.Green got pasted in the front of box. Thus this data is "shared".
Bonos : The Chunk struct
Now that you are convinced that this simple concept of bigger unit of data actually rocks, let's look briefly at an actual code. (version : preview 0.4)
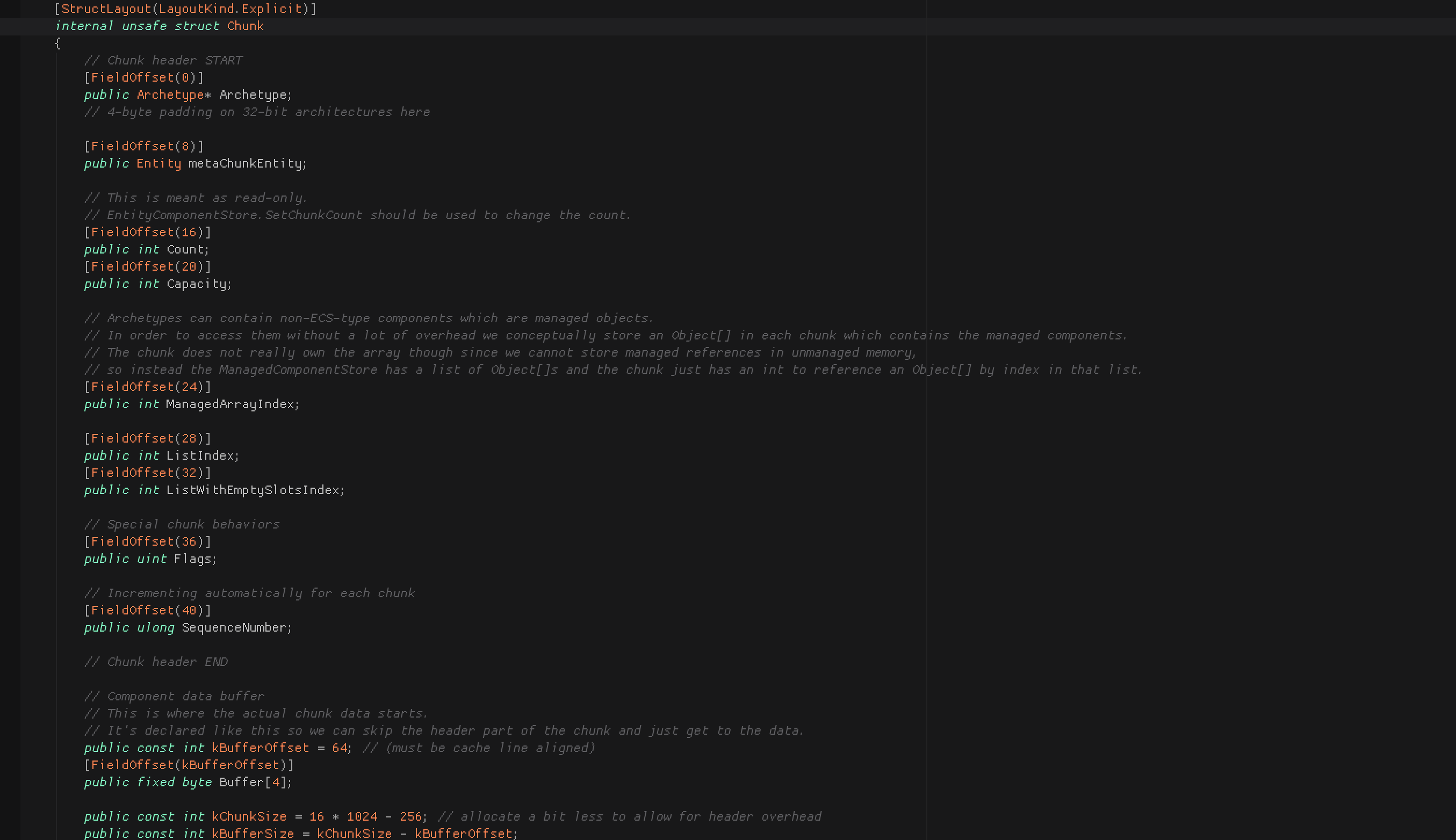
Archetype
The EntityArchetype variable we know and use is just a wrapper over this Archetype pointer type. The archetype contains rich amount of data, but the actual data is not here in the chunk otherwise that would be a waste of space when multiple chunks uses them.. that’s why it is a pointer. The actual data is kept by the ArchetypeManager, which is inside EntityManager , which is one per World .
Meta chunk entity
Chunk got its own special entity other that its actual content. This is for attaching component data on the chunk, the chunk component data. It's neat but it maybe hard to find a use case for this.
Count / Capacity
Count is the amount of Entity in the chunk. It is very important as it all ties to how the next one would be here or find a new chunk to be in. New member is fast to add, old member removed would need adjust data (like grab the last data to fill the hole, then count - 1) so that new one would be able to dumbly add to the end according to count again.
Capacity is a pre calculated max number of entity which can be in here. It is 100% pre calculatable because the chunk’s size is fixed and also we know each component’s size thanks to struct high performance C# restriction.
This ties to an another performance aspect of chunk : each components are listed linearly for each members to the end, before going to the next kind and repeat for all members again. As opposed to OOP where for one "object", all its components are listed before going to the next object.
With some math it is possible to fast skip to the beginning of the component you are interested in, also it is good for your CPU cache as you likely want to see the same component of the next object. For example, when you access your unit's position you are not likely want to use its attack power in the next line of code but it's unfortunate that the attack power memory sits next to position. Instead it is more likely that the code is currently iterating through position of multiple units to do something.
ManagedArrayIndex
A key to go to special storage which can stores any object per entity in this chunk. See here :
https://gametorrahod.com/magical-places-that-store-arbitrary-object-types/