Tag component
Tag component or "zero-sized component" is a special case in Unity ECS where IComponentData doesn't contain any field. The use is to intentionally separate entities to more chunks because a chunk is defined by one set of archetype.


Tag component or "zero-sized component" is a special case in Unity ECS where IComponentData doesn't contain any field.
public struct TagComponent : IComponentData { }
Advantages of tagging
The use is to intentionally separate entities to more chunks because a chunk is defined by one set of archetype. By not having any data, the IComponentData's "data" may sounded wrong but that's when we call it a "tag" instead.
Many "query" in ECS API brought you things in chunk unit. By tagging, you are making it having easier time in bringing you the "filtered" specific data, while not doing any actual element-based filtering (by iteration O(n) regarding to entity amount, etc.) since it is just picking chunks to you without even looking at the data inside.
For example, if you have Name component and Occupation component attach to every entity (to represent a human). Then you also have one ISharedComponentData Sex that has an enum with possible values Male Female Undefined. You know shared component will separate chunks based on its hashed value, so right now the possible chunk archetype you could have are :
NameOccupationSex = MaleNameOccupationSex = FemaleNameOccupationSex = Undefined
Sanity check, it is not necessary that you have exactly 3 chunks. If the chunk is packed with many entities one archetype could span several chunks.
You could have "NEET" in the Occupation component data, but you want it to be special because you are going to do something to all the NEETs a lot. You are thinking about separating those entities that are NEET to a new chunk. You created a NEET tag component. (You have a self defined rule that Occupation on entity that contains NEET tag is meaningless)
The possible chunk archetype you could have are now :
NameOccupationSex = MaleNameOccupationSex = FemaleNameOccupationSex = UndefinedNameOccupationNEETSex = MaleNameOccupationNEETSex = FemaleNameOccupationNEETSex = Undefined
No matter how many chunks each archetype has, it is now fast to get those chunks with NEET. Some example :
EntityQuerywithNEETcould be used to get all the chunks withNEETregardless ofSexor other components. It could leads toTo_API, chunk iteration API,ForEachAPI.IJobForEach<Name>with an attribute[RequireComponentTag(typeof(NEET))]and scheduled withoutEntityQueryargument. (where it would ignore all your attributes in that case) It previously returns all 6 type of chunks without the attribute, but now only those withNEET. This "filtering" is very fast as it sift through chunks, not each entity.- Many
EntityManagercommands hasEntityQuerybatched overload where it does work based on the whole chunk (on all entities in a chunk, not on "chunk component") rather than per entity, and prevents data movement between chunk even on costly sounding action such as add/removing component.
You can easily change theSextoUndefinedfor allNEETfor example. If you instead store the state "NEET" inOccupation, you would have to iterate through all entities withOccupationandifcheck on each, which is not onlyO(n)but also causing data movement on every step you do.
Special treatments in the source code
Tag components are not just ComponentType with no data.
- They will not ever become a read/write dependency.
- Adding/removing tag component to an entity is cheaper compared to non-tag component, since we could skip adding/removing the actual data, saving memory write. (Even though you are explicitly
newing it likeem.AddComponentData(entity, new NEET());) I am not talking about chunk movement yet, both tag and non-tag cause data movement. - When adding tag component via
EntityCommandBuffer, you will also save the internal buffer memory it used to hold your commands because it don't have to remember the field value. - You get a special error when trying to use tag component in
Entities.ForEachlambda argument, so you move them to the.WithAllpart instead. - Adding/removing tag component to all entities in a chunk via batched
EntityManagercommand is a lot cheaper. If you add normal component, a new chunk with an entirely new data layout has to be prepared. What preparation? Remember that chunks are arranged in SOA (Structure of Array). If your component has even one little data inside it, the chunk will have to allocate a contiguous space for that times chunk's capacity (how many entities can fit in given the archetype). But if a tag component, it doesn't have to care!
Example usages
A system DistanceToNearestShop where it is able to ensure all entities with Home component, will have an up to date ShopDistance with a single float field describing straight line distance from home to the closest shop, where each shop is an entity with Shop component. Both Home and Shop has Position XY as in overhead view from the map.
It is a system to find where would be each house's nearest convenience store, and you maybe able to open your own store to take advantage of home that have to walk far to the nearest store, for example.
It would be bad if this system updates every frame with barely nothing new. You then think how to only work when required. The thing is if a new Shop entity appears, it may affects multiple Home (but not all) which they have to change their nearest shop. If a new Home appears, then you only compute that Home according to the current available Shop in the entities world.
Not so good design
Homestarts withoutShopDistance.- The system looking for
Homewith none-queryShopDistanceand add the component along with the computation. This works when you add any newHome, but this is a structural change. TheHomestarts in a different chunk then join together with other homes that hasShopDistance. - To handle the new
Shopproblem, instead of trying to determine affectedHomethat need changes you want to do something simpler. Just remove allShopDistancefrom everything across the board. The previous bullet point then works to recompute everything considering the newShopplacement because allHomenow missingShopDistance. The component removal can be done efficiently with the batched overload ofEntityManager, but nonetheless a structural change becauseShopDistancehas data content inside. You pay a structural change again when the previous bullet point add that back.
Better design
Homestarts withShopDistanceandNeedRecomputetag component.- The 2nd bullet point that previously looking for none
ShopDistance, instead look for bothShopDistanceandNeedRecompute. After computation, useEntityManagerbatched overload to removeNeedRecomputetag component. When a tag component (zero data) is used, it is a special chunk operation that requires no rearrangement of the chunk. It just go straight to the chunk header and tell it the tag is removed. - When a new
Shopis added, you can still perform a simple recompute everything except that you mass-tag everything withNeedRecompute. Again, using zero-sized tag component withEntityManager's chunk/batched overload make it special that there is no data movement required. - A recurring theme is that, an "incomplete component" is better be there from the beginning instead of missing, then mark that incompleteness with a tag component instead. Because we are working data-oriented, the less times data structure has to change, the better.
An even better design is to determine what Home is affected by the newly added Shop, but for the sake of this article let's pretend we don't have enough IQ for that.
The anti-tagging camp
A lot of gains are available after tagging. Most ECS practitioners concerned when we are tagging. Tagging gave us advantages by separating entities to more chunks, that separation is memory copy.
What if we tag often (like every frame) and it cause too many data movements between chunks? You started to fear that the query speed up available after tagging would be outweighted by these chunk data movement.
In this case, wouldn't it be better if we just have NEET boolean field in Occupation and we just iterate through them all and check?
Facts about chunk movement
Before you fear about the cost of tagging, make sure you know what is actually this "chunk movement" when we attach a component to an entity.
- The tagged entity cannot stay in its chunk anymore, since archetype changed.
- If destination chunk with the new tag component/without the removed tag component doesn't exist, allocate it. This allocation doesn't necessary has to be
malloc, it could reuse "chunk hole" that was freed earlier. Saving you a bit of time if that is the case. - When the destination is confirmed, we move the entity data to that destination chunk.
- The old "entity hole" left at the old chunk is replaced by the final entity of that old chunk. The final entity is now ignored by reducing entity count of the chunk. It is not like we have to move all entities after that point back by one step to restore tightly packed memory.
- This has to be on the main thread, or on worker thread with help from
ExclusiveEntityTransactionbut you can't touch the same world'sEntityManagerin the main thread in that mean time. - None of these occur if you are using
EntityQueryoverload ofEntityManagerwhere it operates on everything in a chunk equally. - Writing could also use the same cache technology as reading. It could write to the (faster) cache memory first then by some kind of policy, write it to slower and more permanent memory later. This policy is for example, when the cache entry is being replaced. It depends on your CPU. So, tagging many entities in a row may save you some performance depending on where they would be written to.
So maybe you could see chunk movements are not as costly as you think? Still, noting is certain based on your situation. You might be guessing your SIMD and threaded if Occupation could beat main thread chunk movment. But also remember that if means branching assembly, and they are costly in their own way.
The only way to find out is to profile it. And here I will provide my own benchmark.
Benchmarking tag components
Suppose we have many entities but we would like to work on only some of them. There are 2 approaches :
- "Mark" : You have some kind of check, and if this is
true, you work only on this entity. Advantage is that we don't have to pay for chunk movement cost on tagging entities one by one. Disadvantage is that we cannot skip work, we must always iterate through all and check which one to work on. - "Tag" : Utilize the chunk unit of query in Unity ECS. When adding a component tag, the entity would change its archetype and cannot stay in the same chunk as those not tagged. Then
EntityQuerycould bring in only the chunks that contains the tag and we can work on these entities without anyifin the code, because we already pay for theifwhen we decided to tag or not. Disadvantage is that we must pay for chunk movement cost in addition to thatifto decide to tag. But an advantage is that we can keep using these tagged chunks for extended period of time where the mark approach must always iterate through all entities.
In this test, tagging is queued intoEntityCommandBufferwhile in bursted main threadEntities.ForEachthat contains conditional checks which one should be tagged, then playback out of that, then an another burstedEntities.ForEachwork on those tagged entities. - "Affected entities" : Entities that must be tagged then worked on, or entities that returns
trueon conditional checking and will be worked on in the case of marking.
struct Work : IComponentData
{
public int id; //<-- use to determine whether to mark or tag.
public int value; //<-- work on this.
}
struct Mark : IComponentData
{
public bool marked;
}
struct TagMark : IComponentData
{
}
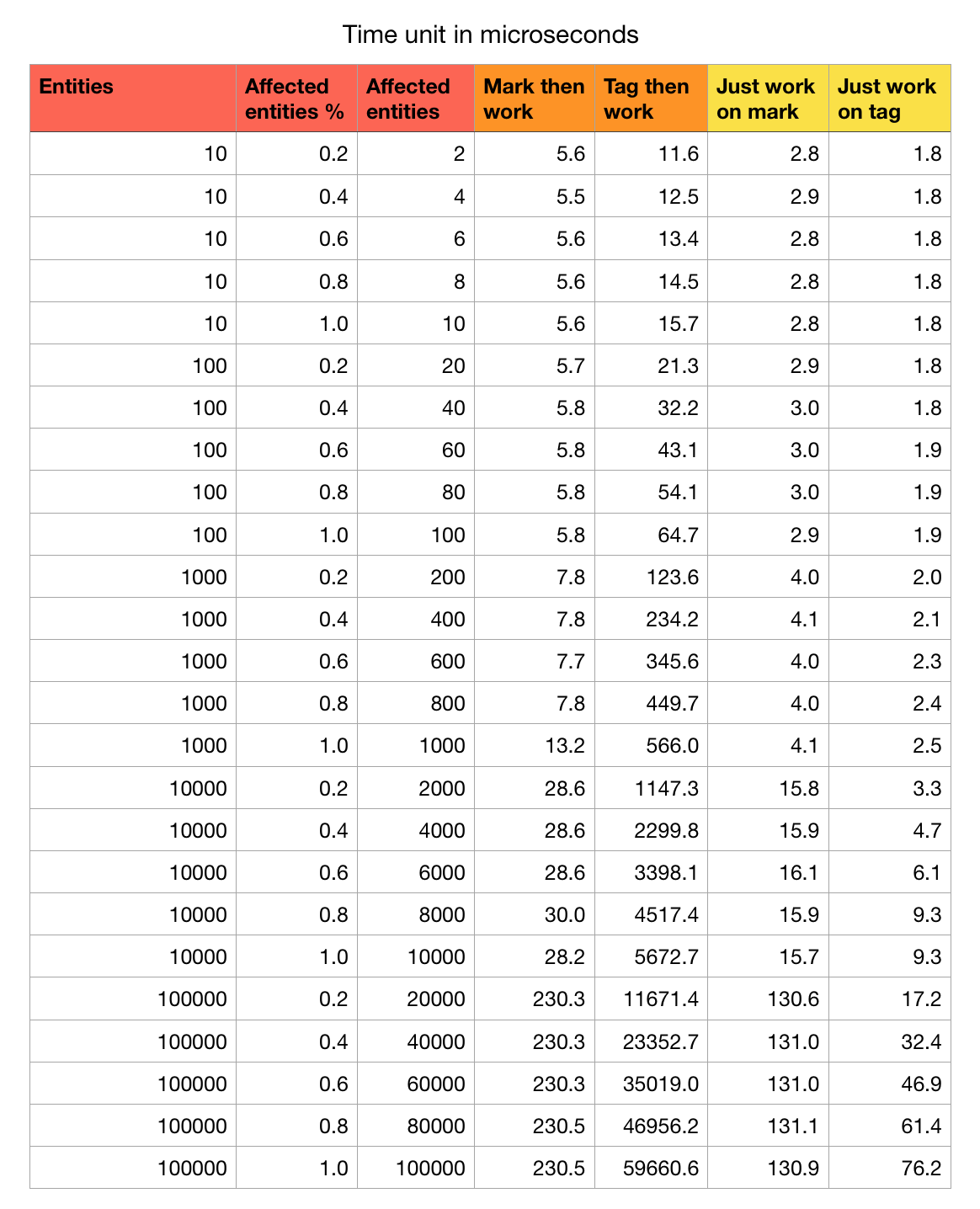
Analysis
- If not counting the tagging cost, by iterating through only the tagged entities without worry about checks cost about half cheaper of the marked equivalent. (The work in this test is adding
100to anint.) - If the work target changes that often that it results in this much tagging consistently each frame, you are better off with just conditional on some data. (Anyways, can you design to avoid this and use tag in the first few frames or less often instead?)
- If you can tag once in a now loading screen or something then keep using the tagged chunks, tagging almost always worth it.
- You may consider mixed approach, tag some, add SCD to some for
EntityQueryfilter, then still have inneriffor detailed checks. Going all the way to remove allifmaybe too much especially those that could be an inline-if:. If theiflooks more like a control flow that could be solved with tagging, it is likely that tagging will benefit. - For example if your RTS game unit has 3 ranks, and when the rank is 3, you want those to have a boosted attack power by x1.5. Maybe tagging
MaxRankto them so that you can boost attacks withoutifis going too far, when you can use inline-if to multiply by either1or1.5fdepending on ifrankfield is== 3or not. You may better keep them in the same chunk for more iteration continuity of other operations. - The take away I got is while it sounds like everything in ECS is fast and we are trying to utilize the C too much, sometimes I forgot that just plainly iterate things also got boosted by Burst, linear array, etc. so it could be just as fast in its own way. Less components means longer length of these linear arrays.
Notes
- Using Entities 0.4.0 preview.10, Burst 1.2.0 preview.11. In editor, MacBook Pro Early 2015, Burst on, safety checks off, leaks detection off.
- I gave an edge to the mark approach by using inline-if where both side returns a value. This results in a better assembly that do not require logic branching (conditional move : CMOV). In real program, you may have a real
ifthat costs more than this per entity. - Tagging may also cost more if other component that did have data on the entity to be moved is larger. This test is just one
int. - The
boolfor marking case here has been separated into its own component of just aboolinstead of making aboolfield to the work componenet. This is to make a linear array of just bools to help the outer if to be as fast as possible while searching them. (Get extra bools in each cache line read instead of getting contents not related to the check, sofalsecase get better performance.) This is to get marking more even with the tagging's fast chunk query.
What if the entity that we tag has a bigger size?
The previous case is just 2 int per entity, plus one bool on an another component. To simulate real use case, I am going to attach this while not using it in any way in the test.
struct Junks : IComponentData //<-- add this component
{
public Junk junk1;
public Junk junk2;
public Junk junk3;
public Junk junk4;
public Junk junk5;
public Junk junk6;
public Junk junk7;
public Junk junk8;
}
struct Junk
{
public int4 i1;
public int4 i2;
public int4 i3;
public int4 i4;
public int4 i5;
public int4 i6;
public int4 i7;
public int4 i8;
}
Additional 4*4*8*8 = 1024 bytes added to each entity. Because chunk is 16kB, the chunk capacity now should be around only 15 entities. Maybe this is a bit excessive but let's see. Data wise this is why both mark and tag case would take a hit in performance from this unrelated component :
- Mark : When we iterate to check
bool, remember that each element came from separated chunks. When the chunk capacity is low, we cross chunk border more often. The query that brought you chunks in the first place would have to work more also. - Tag : When tagging and moving entity out of chunk to a new one, we pay 2 copy cost for moving it along with all its component away, and copy swap back the last element of old chunk to fill its hole. Also when chunk capacity is low, we may also have to reserve new chunk more often. This is added on top of chunk crossing on iteration like the marking method.
Also I will do this as well, instead of adding a Junks component, I add that as a wasted large field in the same component we work on instead.
struct Work : IComponentData
{
public int id; //<-- use to determine whether to mark or tag.
public int value; //<-- work on this.
public Junks junks;
}
This is bad because as we iterate to work on the value field, the remaining data that we would get for free in one cache line read would be junks instead of next component. Using small component benefits performance because of this.
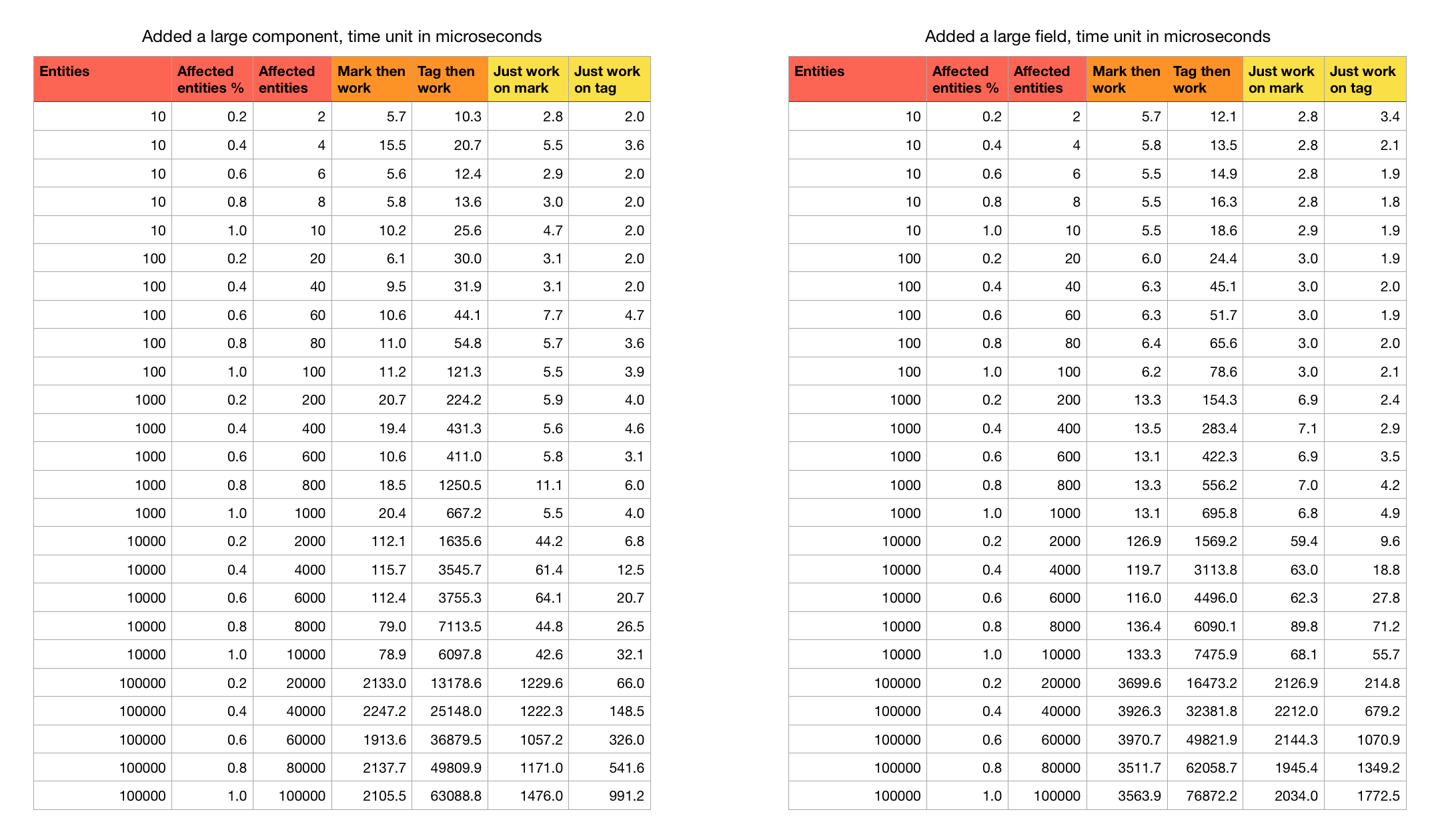
Analysis
- Looks like the marking way take a big performance hit at some threshold. It should be related to something about device's cache size that while iterating it has to go to RAM more often.
- Both case I think took similar performance hit. It is not that tagging or marking way would scales more well on larger entity.
All three side by side :
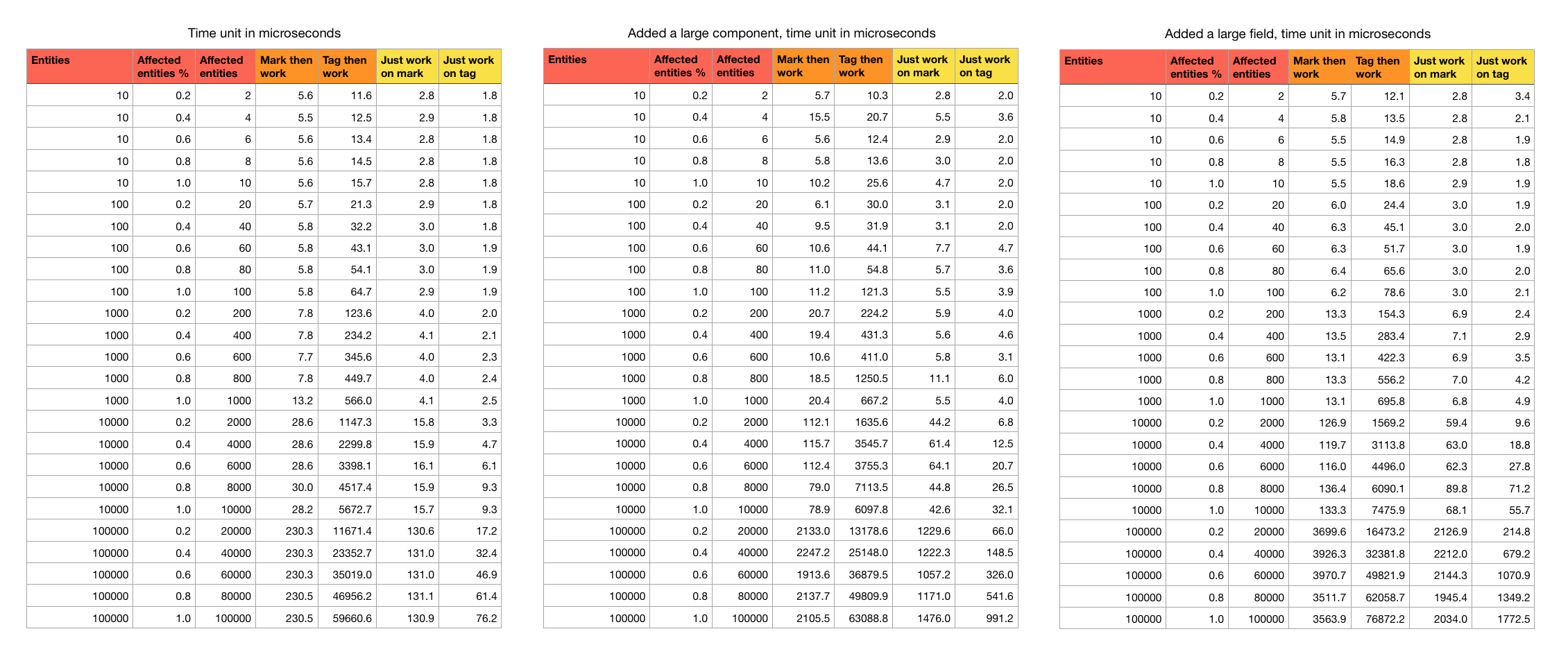
Test code
https://gist.github.com/5argon/849144dd3e766f415c08526dbfa0dcf6
The thing about if
ifdisrupts instruction cache and branch predictor need to work. With tag components, it is possible to "de-if" your entire program making work for processor more linear and predictable, while not causing much data movement cost in return.- If you can replace
ifwith inline conditional:where both sides returns a value instead of a branch in code path, the assembly generated is conditional movecmovwhich is better for the instruction pipeline since it could just run both sides and discard one answer later, instead of having to backtrack.
Remember
- If you could do per-chunk
EntityManageraction it is a no brainer to use tags instead ofifthe value. (So try to design the game this way, maybe cleverly usingISharedComponentDatathat things you want to tag are always grouped.) - You are still encouraged to benchmark your own game! Do not trust this benchmark too much as it is too simple. There is a better performance testing package available now. You should try that.